Stable Diffusion 在图像生成领域的知名度不亚于对话大模型中的 ChatGPT。其能够在几十秒内为任何给定的输入文本创建逼真图像。由于 Stable Diffusion 的参数量超过 10 亿,并且由于设备上的计算和内存资源有限,因而这种模型主要运行在云端。
在没有精心设计和实施的情况下,在设备上运行这些模型可能会导致延迟增加,这是由于迭代降噪过程和内存消耗过多造成的。
如何在设备端运行 Stable Diffusion 引起了大家的研究兴趣,此前,有研究者开发了一个应用程序,该应用在 iPhone 14 Pro 上使用 Stable Diffusion 生成图片仅需一分钟,使用大约 2GiB 的应用内存。
此前苹果也对此做了一些优化,他们在 iPhone、iPad、Mac 等设备上,半分钟就能生成一张分辨率 512×512 的图像。高通紧随其后,在安卓手机端运行 Stable Diffusion v1.5 ,不到 15 秒生成分辨率 512×512 的图像。
近日,谷歌发表的一篇论文中《 Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations 》,他们实现了在 GPU 驱动的设备上运行 Stable Diffusion 1.4 ,达到 SOTA 推理延迟性能(在三星 S23 Ultra 上,通过 20 次迭代生成 512 × 512 的图像仅需 11.5 秒)。此外,该研究不是只针对一种设备;相反,它是一种通用方法,适用于改进所有潜在扩散模型。
在没有数据连接或云服务器的情况下,这项研究为在手机上本地运行生成 AI 开辟了许多可能性。Stable Diffusion 去年秋天才发布,今天已经可以塞进设备运行,可见这个领域发展速度有多快。

论文地址:https://arxiv.org/pdf/2304.11267.pdf
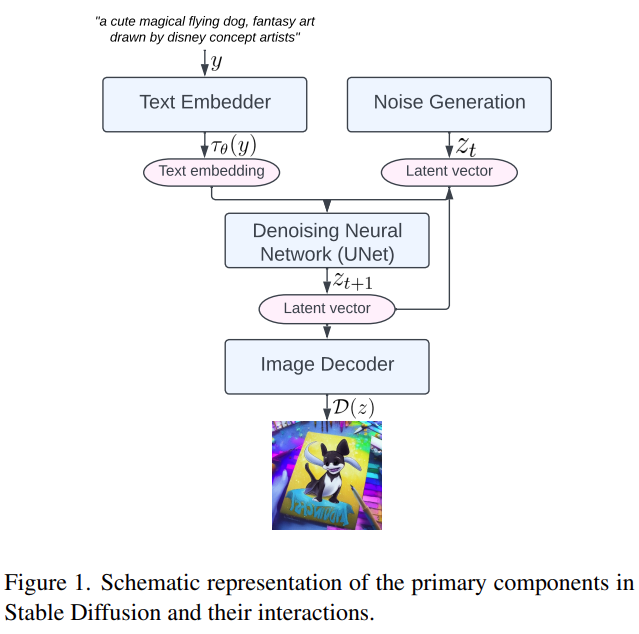
该研究旨在提出优化方法来提高大型扩散模型文生图的速度,其中针对 Stable Diffusion 提出一些优化建议,这些优化建议也适用于其他大型扩散模型。首先来看一下 Stable Diffusion 的主要组成部分,包括:文本嵌入器(text embedder)、噪声生成(noise generation)、去噪神经网络(denoising neural network)和图像解码器(image decoder,如下图 1 所示。