Can Large Language Models Be an Alternative to Human Evaluations?
解决问题:
本文探讨使用大型语言模型(LLMs)是否可以作为评估自然语言处理模型的替代方法,解决了人工评估的不可重复性和不稳定性问题。这是一个新问题。
关键思路:
本文使用LLMs对两个NLP任务进行评估,结果与人工评估结果一致。作者探索了使用LLMs评估文本质量的潜力,并讨论了LLM评估的局限性和伦理考虑。相比目前领域内的研究,本文的新意在于提出了使用LLMs进行文本评估的方法。
其他亮点:
本文使用了两个NLP任务(开放式故事生成和对抗性攻击)的人工评估和LLM评估进行比较,并发现LLM评估结果的稳定性与人工评估相当。该研究未开源代码,但作者提供了数据集的下载链接。这项工作值得继续深入研究,以探索更多使用LLMs进行文本评估的可能性。
关于作者:
本文的主要作者是Cheng-Han Chiang和Hung-yi Lee。他们分别来自台湾大学和台湾科技大学。Cheng-Han Chiang的代表作包括“Learning to Generate One-sentence Biographies from Wikidata”和“Neural Machine Translation with Reconstruction”. Hung-yi Lee的代表作包括“Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features”和“Convolutional Neural Networks for Sentence Classification”。
相关研究:
近期其他相关的研究包括“BERTScore: Evaluating Text Generation with BERT”(Tianyi Zhang等,2020,IBM Research AI)、“A Large-Scale Study on Language Models’ Ability to Recognize Textual Entailment and Contradiction”(Yixin Nie等,2020,University of Texas at Austin)、“Evaluating Text GANs as Language Models”(Yizhe Zhang等,2020,University of California, Santa Cruz)。
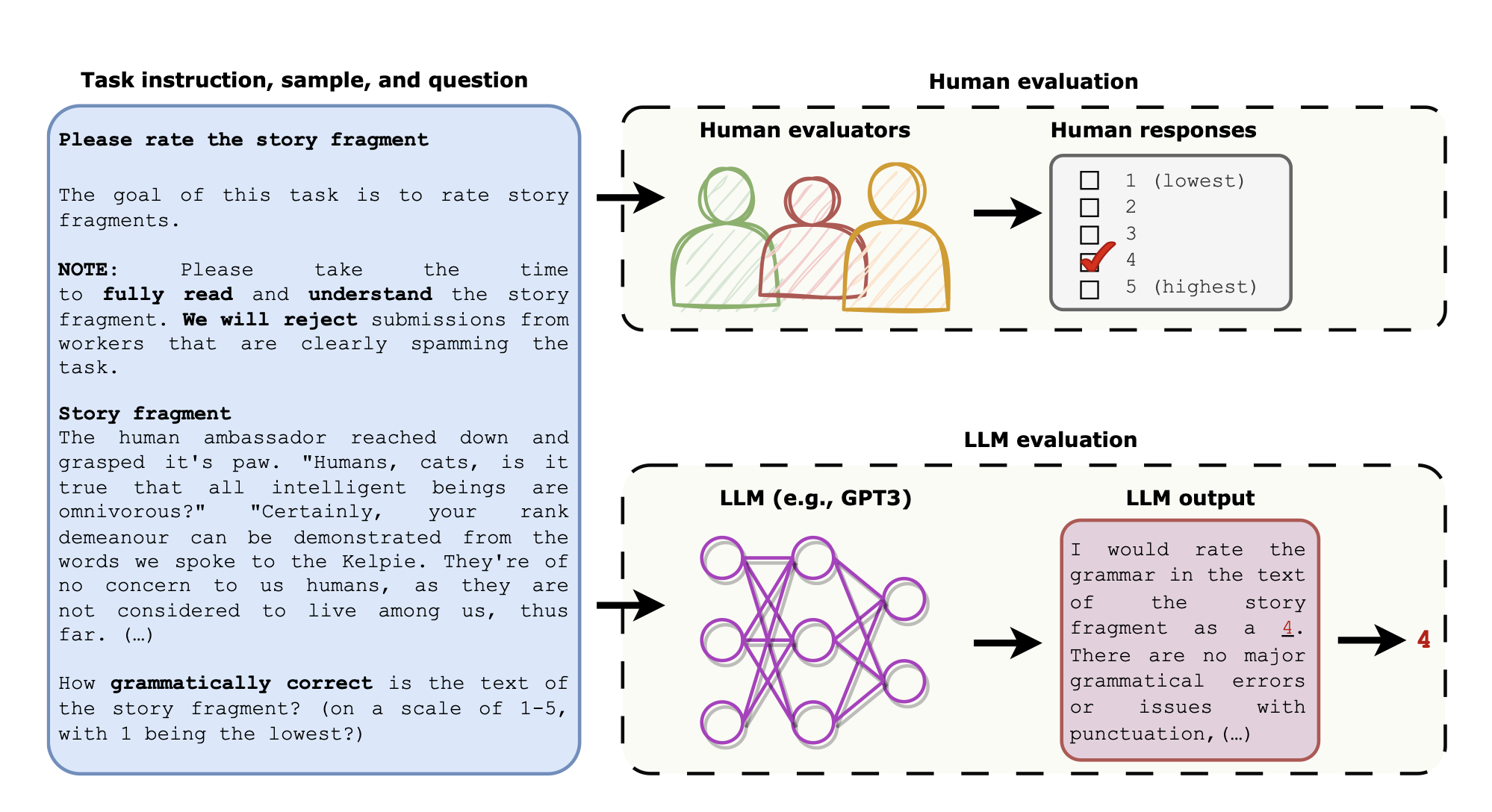
本文探讨了大型语言模型(LLMs)能否作为人类评价的替代品。人类评价对于评估机器学习模型生成的文本或人类编写的文本的质量是必不可少的,但是人类评价非常难以复制,其质量也是不稳定的,这阻碍了不同自然语言处理(NLP)模型和算法之间的公平比较。最近,大型语言模型(LLMs)在仅提供任务说明的情况下,在看不见的任务上表现出了异常的性能。
本文提出了LLMs评估方法,即将完全相同的指令、样本和问题提供给LLMs,然后要求LLMs生成回答这些问题的答案。我们使用人类评价和LLMs评价来评估两个NLP任务中的文本:开放式故事生成和对抗性攻击。我们发现LLMs评价的结果与专家人类评价所得到的结果一致:人类专家评价高的文本也被LLMs评价为高。我们还发现,LLMs评价的结果在任务指令的不同格式和用于生成答案的抽样算法的不同情况下是稳定的。我们是第一个展示使用LLMs评估文本质量的潜力,并讨论了LLMs评估的局限性和伦理考虑。
相关文章
