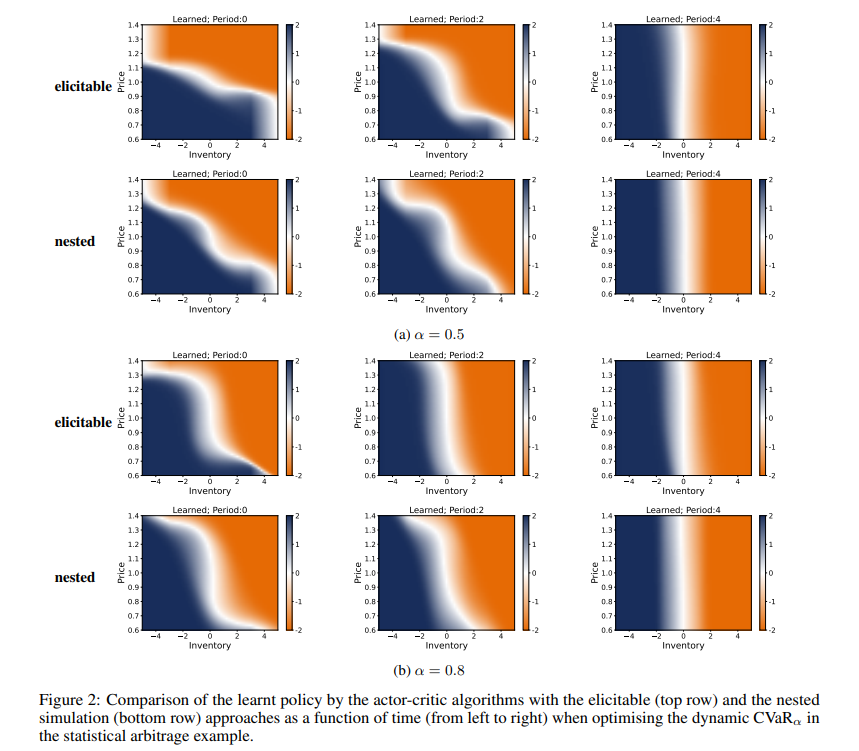
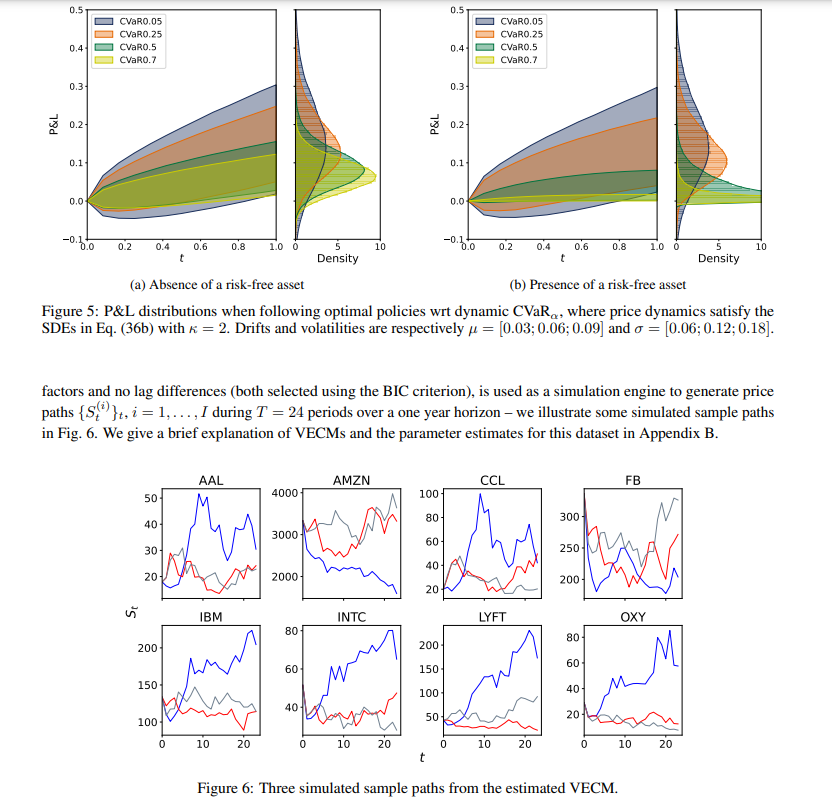
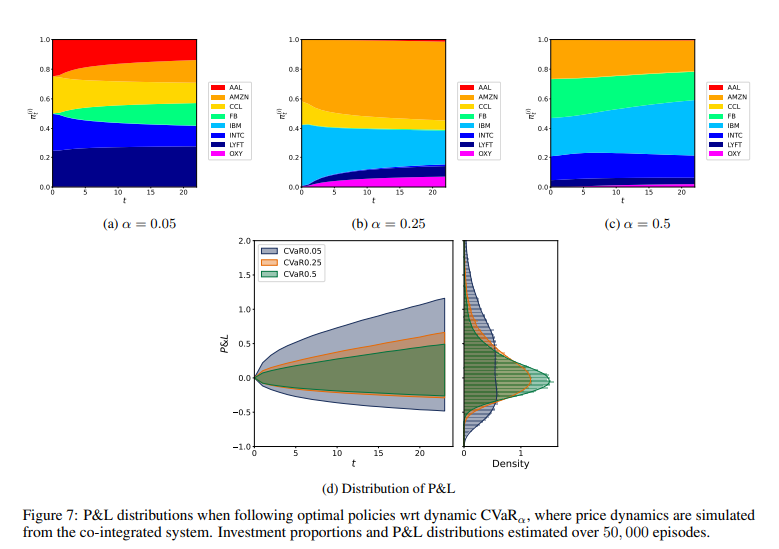
【标题】Conditionally Elicitable Dynamic Risk Measures for Deep Reinforcement Learning
【作者团队】Anthony Coache, Sebastian Jaimungal, Álvaro Cartea
【发表日期】2022.6.29
【论文链接】https://arxiv.org/pdf/2206.14666.pdf
【推荐理由】本文提出了一种新的框架来解决风险敏感强化学习(RL)问题,其中智能体优化了时间一致的动态频谱风险度量。基于条件可诱导性的概念,该方法构造了(严格一致的)评分函数,在估计过程中用作惩罚因子。主要贡献有三个方面:(i)设计了一种有效的方法,用深度神经网络估计一类动态谱风险测度,(ii)证明这些动态谱风险测度可以用深度神经网络近似到任何任意精度,以及(iii)开发一种风险敏感的演员-评论家算法,该算法使用完整剧集并且不需要任何额外的嵌套转换。并将概念上改进的强化学习算法与嵌套模拟方法进行了比较,并在两种情况下说明了其性能:模拟数据和真实数据上的统计套利和投资组合分配。