Controllable Text-to-Image Generation with GPT-4
Tianjun Zhang, Yi Zhang, Vibhav Vineet, Neel Joshi, Xin Wang
UC Berkeley 、Microsoft Research
目前的文本到图像生成模型往往难以遵循文本指令,尤其是需要空间推理的指令。另一方面,大型语言模型(LLM),如GPT-4,在生成代码片断以图形方式勾勒出文本输入方面表现出显著的精确性,例如,通过TikZ。在这项工作中,我们引入了Control-GPT,用GPT-4生成的程序性草图来指导基于扩散的文本到图像管道,增强其指令跟踪能力。Control-GPT通过查询GPT-4来编写TikZ代码,生成的草图与扩散模型(如ControlNet)的文本指令一起作为参考,以生成照片般真实的图像。
该研究提出了一个简单而有效的框架 Control-GPT,它利用 LLM 的强大功能根据文本 prompt 生成草图。Control-GPT 的工作原理是首先使用 GPT-4 生成 TikZ 代码形式的草图。如下图 1 (c) 所示,程序草图(programmatic sketch)是按照准确的文本说明绘制的,随后这些草图被输入 Control-GPT。Control-GPT 是 Stable Diffusion 的一种变体,它能接受额外的输入,例如参考图像、分割图等等。这些草图会充当扩散模型的参考点,使扩散模型能够更好地理解空间关系和特殊概念,而不是仅仅依赖于文本 prompt。这种方法使得 prompt 工程和草图创建过程不再需要人为干预,并提高了扩散模型的可控性。

训练我们的管道的一个主要挑战是缺乏一个包含对齐的文本、图像和草图的数据集。我们通过将现有数据集中的实例掩码转换为多边形来解决这个问题,以模仿测试时使用的草图。因此,Control-GPT大大提升了图像生成的可控性。它在空间排列和物体定位生成方面建立了新的技术水平,增强了用户对物体位置、尺寸等的控制,使先前模型的精确度提高了近一倍。我们的工作,作为第一次尝试,显示了采用LLMs来提高计算机视觉任务性能的潜力。
方法
对图像生成来说,训练过程的一个较大挑战是缺乏包含对齐文本和图像的数据集。为了解决这个难题,该研究将现有实例分割数据集(例如 COCO 和 LVIS)中的实例掩码转换为多边形的表示形式,这与 GPT-4 生成的草图类似。
然后,该研究构建了一个包含图像、文本描述和多边形草图的三元数据集,并微调了 ControlNet。该研究发现这种方法有助于更好地理解 GPT 生成的草图,并且可以帮助模型更好地遵循文本 prompt 指令。
ControlNet 是扩散模型的一种变体,它需要额外的输入条件。该研究使用 ControlNet 作为基础图像生成模型,并通过编程草图和 grounding token 的路径对其进行扩展。
实验
基于 Visor 数据集,研究者对 Control-GPT 进行了一系列实验设置的评估,测试其在空间关系、物体位置和大小方面的可控性。他们还将评估扩展到多个物体和分布外的 prompt。广泛的实验表明,Control-GPT 可以大大提升扩散模型的可控性。
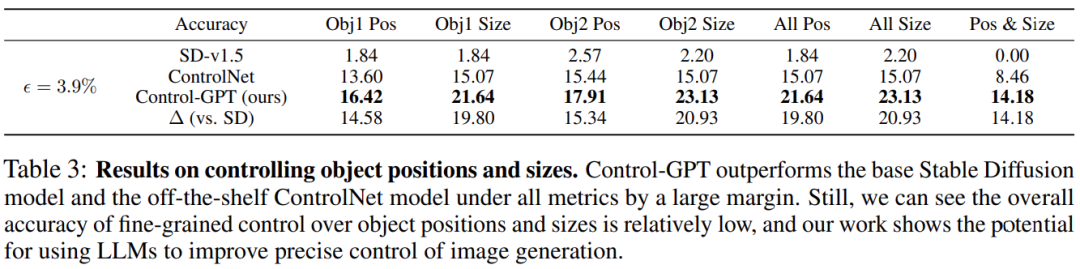
下表 3 中列出了定量评估结果。可以看到,Control-GPT 模型可以在给定的一些规格下更好地控制物体的大小和位置。与几乎无法控制物体位置和尺寸的 Stable Diffusion 模型(SD-v1.5)相比,Control-GPT 将总体精度从 0% 提高到 14.18%。与现成的 ControlNet 相比,Control-GPT 在所有指标上也取得了更好的表现,获得了从 8.46% 到 4.18% 的整体改善。这些结果展示了本文的 LLM 集成框架在更细化和精确控制图像生成过程方面的潜力。
视觉化。下图 6 展示了定性评估结果,可以看到,ControlGPT 可以按照物体位置和尺寸的规范绘制物体。相比之下,ControlNet 也能遵循,但却很难生成正确的物体,而 Stable Diffusion 则无法遵循规范。

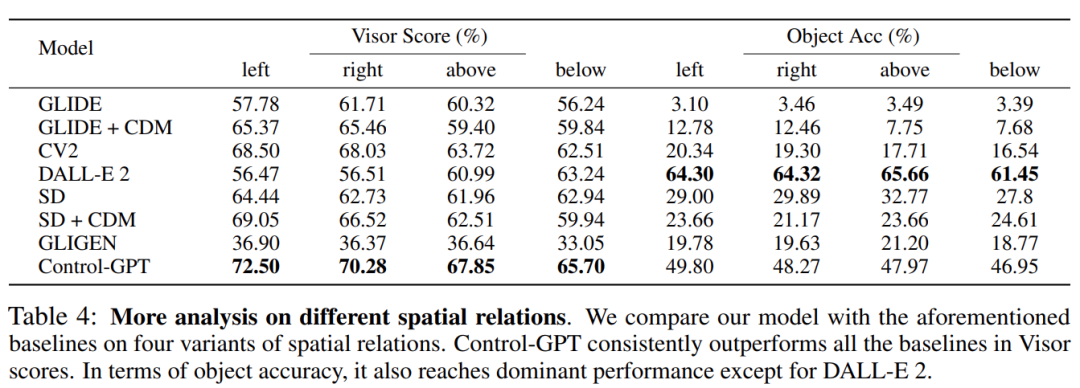
对空间关系的消融实验。研究者还探讨了模型是否对不同类型的空间关系(如左 / 右 / 上 / 下)有偏好,作为空间关系基准分析的一部分。从下表 4 中可以看出,Control-GPT 在 Visor Score 和物体准确性方面一直比所有的基线模型工作得更好。
多个物体之间的关系。研究者对 Control-GPT 生成多个物体的能力进行了进一步的评估,这些物体的空间关系由 prompt 指定。下图 7 展示了一些例子,Control-GPT 能理解不同物体之间的空间关系,并在 GPT-4 的帮助下将它们放入布局中,表现出了更好的性能。

可控性与图像逼真度。通常,在生成逼真图像与遵循精确布局之间往往存在着妥协,特别是对于分布外的文字 prompt。如下图 8 所示,(a)是一个例子,生成的图像完全遵循布局,但这导致了图像中的一些伪影;而在(b)中,照片往往看起来很逼真,但没有很好地遵循草图。
相关文章
