【标题】Recursive Reinforcement Learning
【作者团队】Ernst Moritz Hahn, Mateo Perez, Sven Schewe, Fabio Somenzi, Ashutosh Trivedi, Dominik Wojtczak
【发表日期】2022.6.23
【论文链接】https://arxiv.org/pdf/2206.11430.pdf
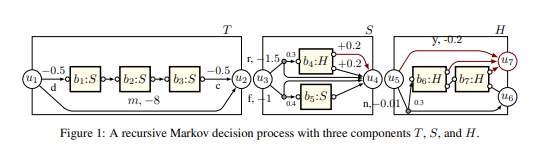
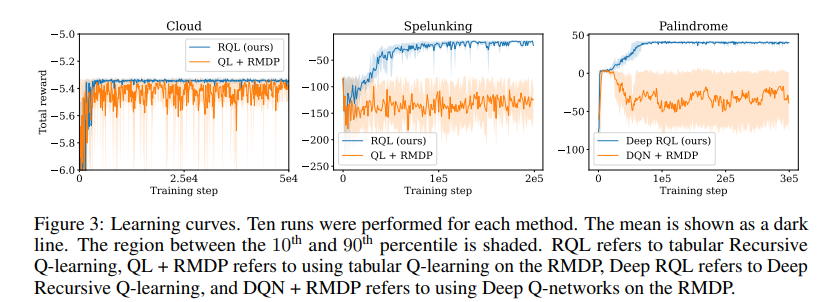
【推荐理由】循环是有限描述潜在无限对象的基本范式。由于最先进的强化学习(RL)算法无法直接对循环进行推理,它们必须依靠实践者的创造力来设计环境的合适“平面”表示。由此产生的手动特征构造和近似非常繁琐且容易出错;它们缺乏透明度妨碍了可扩展性。为此,本文提出能够在环境中计算最优策略的 RL 算法,这些环境被描述为可以循环调用彼此的马尔可夫决策过程 (MDP) 的集合。每个组成MDP都有几个入口和出口点,对应于这些调用的输入和输出值。这些循环MDP(或RMDP)在表达上等价于概率下推系统(调用堆栈扮演下推堆栈的角色),并且可以使用循环过程调用对概率程序进行建模。最后引入了循环Q学习——RMDPs的一种无模型RL算法,并证明了它在温和的假设下收敛于有限、单出口和确定性多出口RMDPs。