Blockwise Parallel Transformer for Long Context Large Models
Hao Liu, Pieter Abbeel
[UC Berkeley]
要点:
-
动机:解决自注意力机制和大型前馈网络在Transformer中带来的内存需求问题,以处理长序列和长程依赖性任务。 -
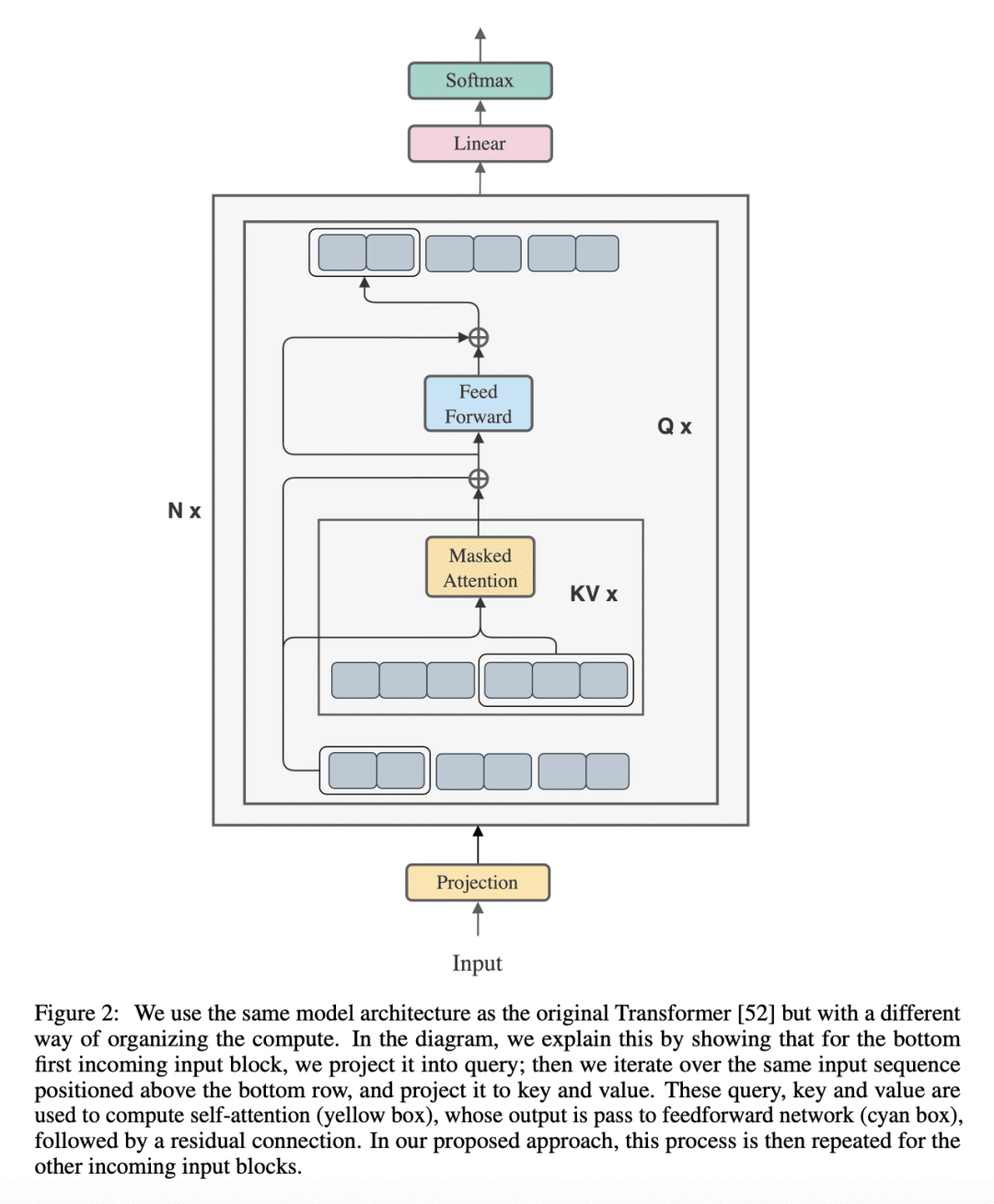
方法:提出一种新方法,即块状并行Transformer(BPT),通过块状计算自注意力和前馈网络融合,以最小化内存成本。 -
优势:BPT可以处理比普通Transformer长32倍的训练序列,并且比之前的内存高效方法能处理2至4倍更长的序列。在语言建模和强化学习任务上进行的大量实验证明了BPT在降低内存要求和提高性能方面的有效性。
提出了块状并行Transformer(BPT)方法,通过块状计算自注意力和前馈网络融合,降低内存需求并处理长序列和长程依赖性任务。
Transformers have emerged as the cornerstone of state-of-the-art natural language processing models, showcasing exceptional performance across a wide range of AI applications. However, the memory demands posed by the self-attention mechanism and the large feedforward network in Transformers limit their ability to handle long sequences, thereby creating challenges for tasks involving multiple long sequences or long-term dependencies. We present a distinct approach, Blockwise Parallel Transformer (BPT), that leverages blockwise computation of self-attention and feedforward network fusion to minimize memory costs. By processing longer input sequences while maintaining memory efficiency, BPT enables training sequences up to 32 times longer than vanilla Transformers and 2 to 4 times longer than previous memory-efficient methods. Extensive experiments on language modeling and reinforcement learning tasks demonstrate the effectiveness of BPT in reducing memory requirements and improving performance.
https://arxiv.org/abs/2305.19370 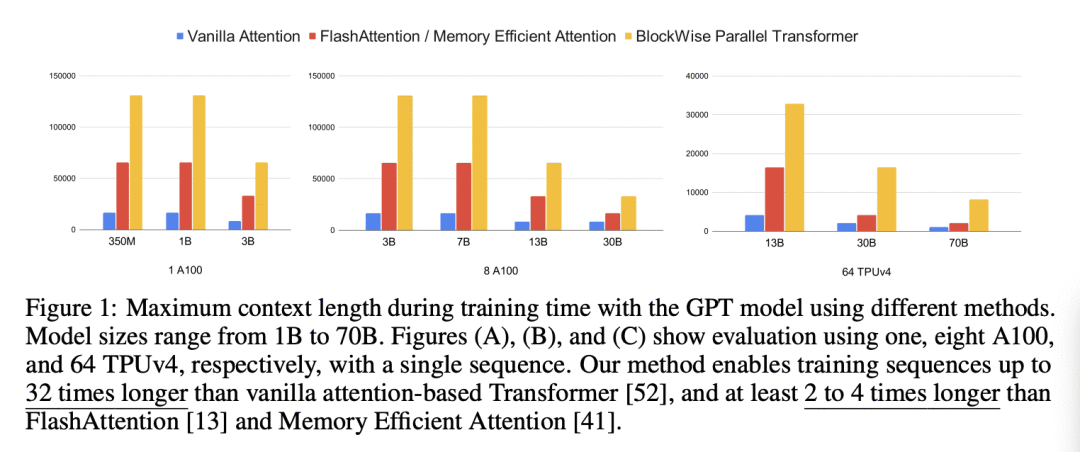

相关文章
