本文转自公众号「老刘说NLP」
大型语言模型的训练分为从原始文本中进行无监督的预训练,以学习通用的表征、大规模的指令调整和强化学习,以更好地适应最终任务和用户偏好两个阶段。
有一种假设认为,大型语言模型中的几乎所有知识都是在预训练中学习的,只需要有限的指导微调数据就可以教会模型产生高质量的输出。
因此, 关于微调数据使用量,具体对微调的性能有怎样的影响,这个话题十分有趣。
在之前的文章《也谈大模型研发中的微调数据规模评估与质量问题:数据规模大小的影响评估、数据主要问题及清洗项目》中我们介绍了《Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases》这一工作,该工作评估instruct-data的训练的影响,结论是:对于翻译、改写、生成和头脑风暴任务,200万甚至更少的数据量可以使模型表现良好。对于提取、分类、封闭式QA和总结摘要任务,模型的性能可以随着数据量的增加而继续提高,这表明仍然可以通过简单地增加训练数据量来提高模型的性能,但改进的潜力可能是有限的。模型在数学、代码和COT上的表现仍然很差,需要在数据质量、模型规模和训练策略上需要做更细致的优化。
而最近包括《LIMA:Less Is More for Alignment》、《MAYBE ONLY 0.5% DATA IS NEEDED》则在说明小数据量上,提出了更新颖的结论。
《LIMa:Less Is More for Alignment》一文的消融实验显示,当扩大数据量而不同时扩大提示多样性时,收益会大大减少,而在优化数据质量时,收益会大大增加。
《MAYBE ONLY 0.5% DATA IS NEEDED》一文的实验表明,特定任务的模型可能从固定的任务类型中获益,以获得更高的性能; 指令格式的多样性可能对特定任务模型的性能影响很小;即使是少量的数据(1.9M tokens)也能为特定任务模型的指令调整带来可喜的结果。
本文对该两个工作进行介绍,这也是从机理上文章解读写的第一篇,越来越觉得,SFT训练,学的是一种模式,一种pattern,供大家一起参考。
一、LIMA: Less Is More for Alignment
论文地址:https://arxiv.org/pdf/2305.11206.pdf
1、浅层对齐假说
浅层对齐假说,即一个模型的知识和能力几乎完全是在预训练中学习的,而对齐则是教它在与用户交互时应该使用哪种子分布的格式。如果这个假说是正确的,而对齐主要是关于学习风格的,那么浅层对齐假说的一个推论是,人们可以用一组相当小的例子充分调整预训练的语言模型。
因此,该工作假设,对齐可以是一个简单的过程,模型学习与用户互动的风格或格式,以揭示在预训练中已经获得的知识和能力。
该工作通过训练LIMA来衡量这两个阶段的相对重要性,LIMA是一个65B参数的LLaMa语言模型,仅在1000个精心标注的提示和回复上用标准的监督损失进行微调,且没有任何强化学习或人类偏好建模。
对应的消融实验显示,当扩大数据量而不同时扩大提示多样性时,收益会大大减少,而在优化数据质量时,收益会大大增加。 此外,尽管没有对话实例,LIMA可以进行连贯的多轮对话,而且这种能力可以通过向训练集添加30条手工制作的多轮对话数据而得到极大的提高。
2、训练样本构造
从三个社区问答网站收集数据:Stack Exchange、wikiHow和Pushshift Reddit数据集。
还是老样子,我们可以通过通过数据构造细节,来加深对数据处理的印象,这个十分有趣且重要。
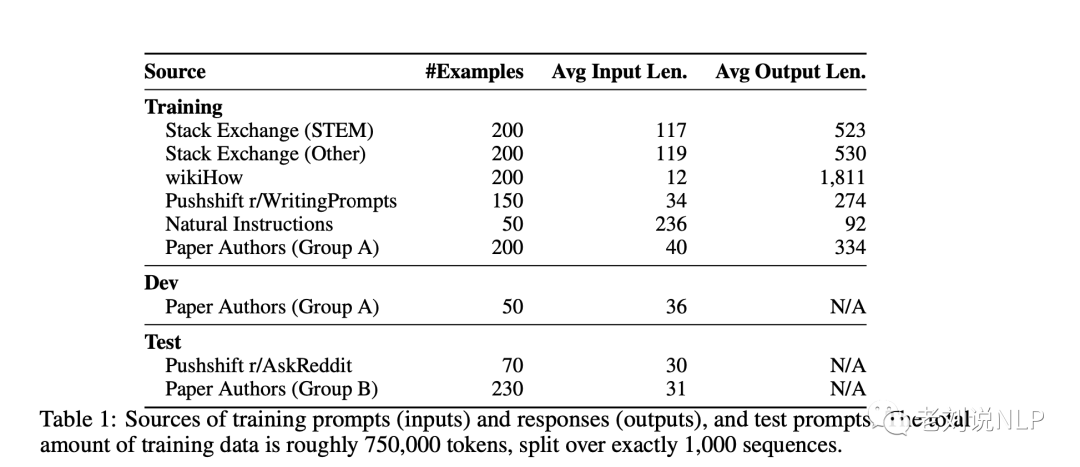
1)Stack Exchange
Stack Exchange包含179个在线社区(交流),每个社区都致力于一个特定的主题,其中最受欢迎的是编程(Stack Overflow)。用户可以发布问题、答案和评论,并对上述所有内容进行加注(或减注)。
在从Stack Exchange采样时,同时采用了质量和多样性控制。首先,将交流分成75个STEM交流(包括编程、数学、物理等)和99个其他(英语、烹饪、旅游等),并放弃了5个小众交流。然后,从每组中抽出200个问题和答案,使用?=3的温度来获得不同领域的更均匀的样本。
在每个交流,选择得分最高的问题,然后选择每个问题的最高答案,并保证它有很强的正面得分(至少10分)。为了符合一个有帮助的人工智能助手的风格,自动过滤那些太短(少于1200个字符)、太长(超过4096个字符)、以第一人称书写(”我”、”我的”)或引用其他答案(”如提到”、”Stack exchange “等)的答案;并从回答中删除链接、图片和其他HTML标签,只保留代码块和列表。
由于Stack Exchange问题同时包含标题和描述,随机选择一些例子的标题作为提示,而其他例子则选择描述。
2)wikiHow
wikiHow是一个在线的维基式出版物,有超过24万篇关于各种主题的方法文章。从wikiHow中抽取了200篇文章,首先抽取一个类别(19个),然后抽取其中的一篇文章,以确保多样性。
使用标题作为提示(例如 “如何做煎蛋?”),并将文章的内容作为回应。
在处理上,用 “下面的答案…… “取代典型的 “这篇文章…… “开头,并采用一些启发式的预处理方法来修剪链接、图片和文本中的某些部分。
3)Pushshift Reddit数据集
Reddit是世界上最受欢迎的网站之一,允许用户在用户创建的subreddits中分享、讨论和加注内容。
在处理上,将样本限制在两个子集,即r/AskReddit和r/WritingPrompts,并从每个社区的最高票数的帖子中手动选择例子。
并从r/AskReddit中找到了70个自成一体的提示(只有标题,没有正文),并将其用作测试集。
WritingPrompts子版块包含虚构故事的前提,然后鼓励其他用户创造性地完成这些故事,共找到150个提示和高质量的回应,包括情诗和短篇科幻小说等主题,并将其加入训练集。
4)人工撰写例子
为了使数据进一步多样化,除了在线社区中用户提出的问题之外,还收集了来自我们自己(这项工作的作者)的提示信息。
指定了两组作者,A组和B组,各创作250个提示,灵感来自他们自己或他们朋友的兴趣。
在过滤了一些有问题的提示后,B组剩下的230条提示被用于测试。
此外,还包括13个具有一定程度毒性或恶意的训练提示。
此外,该工作还选择了50个自然语言生成任务,如总结、转述和风格转换,并从每个任务中随机挑选一个例子,并对其中的一些例子稍作编辑。
3、对比模型与实验效果
为了将LIMA与其他模型进行比较,我们为每个测试提示生成一个单一的反应。然后,我们要求人群工作者将LIMA的输出与每个基线进行比较,并标注他们更喜欢哪一个,该工作将LIMA与五个基线进行比较:
Alpaca 65B ,在Alpaca训练集[Taori et al., 2023]中的52,000个例子上对LLaMa 65B进行了微调;
OpenAI-DaVinci003,一个用人类反馈的强化学习(RLHF)调整的大型语言模型;
谷歌的Bard,基于PaLM;
Anthropic的Claude4,一个用人工智能反馈强化学习(Constitutional AI)训练的52B参数模型
OpenAI的GPT-4,一个用RLHF训练的大型语言模型,目前被认为是最先进的。在整个2023年4月,对所有基线的反应进行了采样。

实验效果如上,图1显示了人类偏好研究的结果,图2显示了GPT-4偏好的结果。结果表明:尽管在52倍的数据上进行训练,Alpaca 65B倾向于产生比LIMA更少的偏好输出。DaVinci003的情况也是如此,尽管优势微弱;
4、讨论与分析
通过消融实验研究训练数据的多样性、质量和数量的影响,对于对齐的目的,扩大输入多样性和输出质量有可衡量的积极影响,而仅仅扩大数量可能没有。
首先,在数量上,从Stack Exchange中抽取指数级增加的训练集。图6显示,有趣的是,训练集的翻倍并没有改善响应质量。这个结果以及我们在本节中的其他发现表明,排列组合的缩放规律不一定只受制于数量,而是在保持高质量响应的同时,提示多样性的功能。
其次,在多样性上,为了测试提示多样性的影响,同时控制质量和数量,比较了训练对经过质量过滤的Stack Exchange数据和wikiHow数据的影响,前者有异质的提示和优秀的回答,后者有同质的提示和优秀的回答。
虽然在将Stack Exchange和wikiHow作为多样性的代表进行比较时,在从两个不同来源的数据中取样(每个来源中抽出2000个训练例子)可能会有其他混淆因素,但图5显示,更多样化的Stack Exchange数据产生了明显更高的性能。
最后,在质量上,为从Stack Exchange中抽取了2000个例子,没有经过任何质量或风格的过滤,并将在这个数据集上训练的模型与在过滤过的数据集上训练的模型进行比较。图5显示,在经过过滤和未经过过滤的数据源上训练的模型之间有0.5分的显著差异。
因此,总结上来说,在1000个精心策划的例子上对一个强大的预训练语言模型进行微调,可以在广泛的提示中产生显著的、有竞争力的结果。
然而,这种方法也有局限性,正如文中阐述的那样:
首先,构建这样的例子所付出的努力是巨大的,而且很难扩大规模。
其次,LIMA并不像产品级模型那样稳健;
尽管如此,这项工作中提出的证据表明,用一种简单的方法来解决复杂的对齐问题是有潜力的。
二、MAYBE ONLY 0.5% DATA IS NEEDED
《MAYBE ONLY 0.5% DATA IS NEEDED: A PRELIMINARY EXPLORATION OF LOW TRAINING DATA INSTRUCTION TUNING》
该工作利用聚类的思想筛选样本进行实验,以说明微调数据规模并不需要难么多,就可以达到一个不错的效果。其实际上走的是多样性的路子。
地址:https://arxiv.org/abs/2305.09246
1、算法原理
1)向量化
将数据重新格式化为指令调优训练阶段使用的训练输入格式,即带有描述指令的数据,在最后加入答案,以格式化一个完整的训练数据。
然后,使用预先训练好的语言模型(如Galactica或Bert)对所有样本进行编码。
具体地,将模型作为单词嵌入或每个句子的输入后,提取每个样本的last_hidden_state。对每个样本的词嵌入进行均值集合,得到一个一维向量作为该样本的句子嵌入。
为了加快计算速度,方便向量相似性的计算,将所有句子嵌入归一为长度1,即对嵌入维度进行L2归一。
2)聚类
考虑到NLP任务边界的模糊性可能导致不同任务的样本之间的差异很小。
因此,通过关注数据表征来进行无监督聚类,而不是依靠标签信息来将数据点基于相同的类别或任务归类。
具体来说,在获得第一步的句子嵌入后,使用K-Means在嵌入空间中进行无监督聚类,以获得每个样本和其对应的聚类标签的映射。
然后,根据一个下游任务的样本出现在几个聚类中的频率,选择频率最高的聚类的中心点作为该下游任务的分布中心点。
接下来,对于任务中的所有样本,计算与分布中心点的余弦相似度(距离函数的选择对结果影响不大,按照OpenAI的方法选择余弦相似度),并从任务数据中找出与该中心点最接近的样本作为任务中心点,任务中心点是这个任务数据中与分布中心点余弦相似度最大的一个确切样本。
3)核心样本采样
在获得下游任务对应的分布中心点后,根据余弦相似度选择最相似的样本作为代表性的任务样本,使用了一种核心集算法KCentergreedy,该算法旨在选择k个中心点,使随机数据点与其最近的中心点之间的最大距离最小。
4、实验数据、模型与结论
1)实验数据
在总共11个数据集上进行了实验,这些数据集横跨4个NLP任务,即自然语言推理(NLI,1.9M tokens)、句子补充(SC,660.6K tokens)、词义歧义(WSD,25.5K tokens)和核心推理(CR,185.1K tokens);
2)实验模型
采用Galactica-1.3b。Galactica模型是在一个庞大的科学语料库中训练出来的,并被定制用于处理科学任务,如引文预测、科学问题回答、数学推理、总结、文档生成、分子特性预测和实体提取;
3)实验结论
当考虑到一个特定的任务(本例中为NLI)时,该方法在NLI任务上实现了比基线(表中P3)平均2%的性能改进,只使用了P3中0.5%的可用数据。
与使用P3的所有10条指令相比,只选择一条指令就能达到与使用P3的整个数据集相媲美的结果,而且只用了10%的数据。
通过在P3数据集上调优NLI任务的Galactica-1.3b模型,最终得出了几个结论:
首先,特定任务的模型可能从固定的任务类型中获益,以获得更高的性能;
其次,指令格式的多样性可能对特定任务模型的性能影响很小【这块有问题,格式的多样并不能通过聚类方法实现】;
最后,即使是少量的数据(1.9M tokens)也能为特定任务模型的指令调整带来不错的结果。
不过,由于计算资源的限制,该工作有一些局限性,比如只在Galactica-1.3b上进行实验,只利用P3数据集中的NLI任务数据。
总结
多样性,高质量这两个数据上的问题一直被认定是决定模型性能的天花板。
在目前的绝大多数微调模型,都是靠着大力出奇迹来实现一个较好的性能,这也是过去几个月大家都在卷数据量的一个真实写照。
但是否想过,openai这种什么技能都能做到的模型,在多样性上应该做了大量的工作,并且在数据量上应该没有太大的追求。
所以,最近的风向变成,是否可以利用少量的数据就能取得差不多的效果,这样的话,努力的方向就可以变成多样性数据的挖掘上,这可能是openai走通但我们没想明白的地方。
《LIMI:Less Is More for Alignment》以及《MAYBE ONLY 0.5% DATA IS NEEDED》两篇文章做了一些初步的实验工作,但不得不说,实验条件相对局限,而且结论地并不能作为定量的参考,这个还需要我们具体实操时具体分析。
参考文献
1、https://arxiv.org/pdf/2305.11206.pdf
2、https://arxiv.org/abs/2305.09246
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
相关文章
