?智源社区日报关注订阅?
来自斯坦福的团队,发布了一款LLM自动评测系统——AlpacaEval,以及对应的AlpacaEval Leaderboard。这个全新的大语言模型排行榜 AlpacaEval,它是一种基于 LLM 的全自动评估基准,且更加快速、廉价和可靠。
项目链接:https://github.com/tatsu-lab/alpaca_eval
排行榜链接:https://tatsu-lab.github.io/alpaca_eval/
该研究团队选择了目前在开源社区很火的开源模型,还有GPT-4、PaLM 2等众多「闭源」模型,甚至还开设了一个「准中文」排行榜。
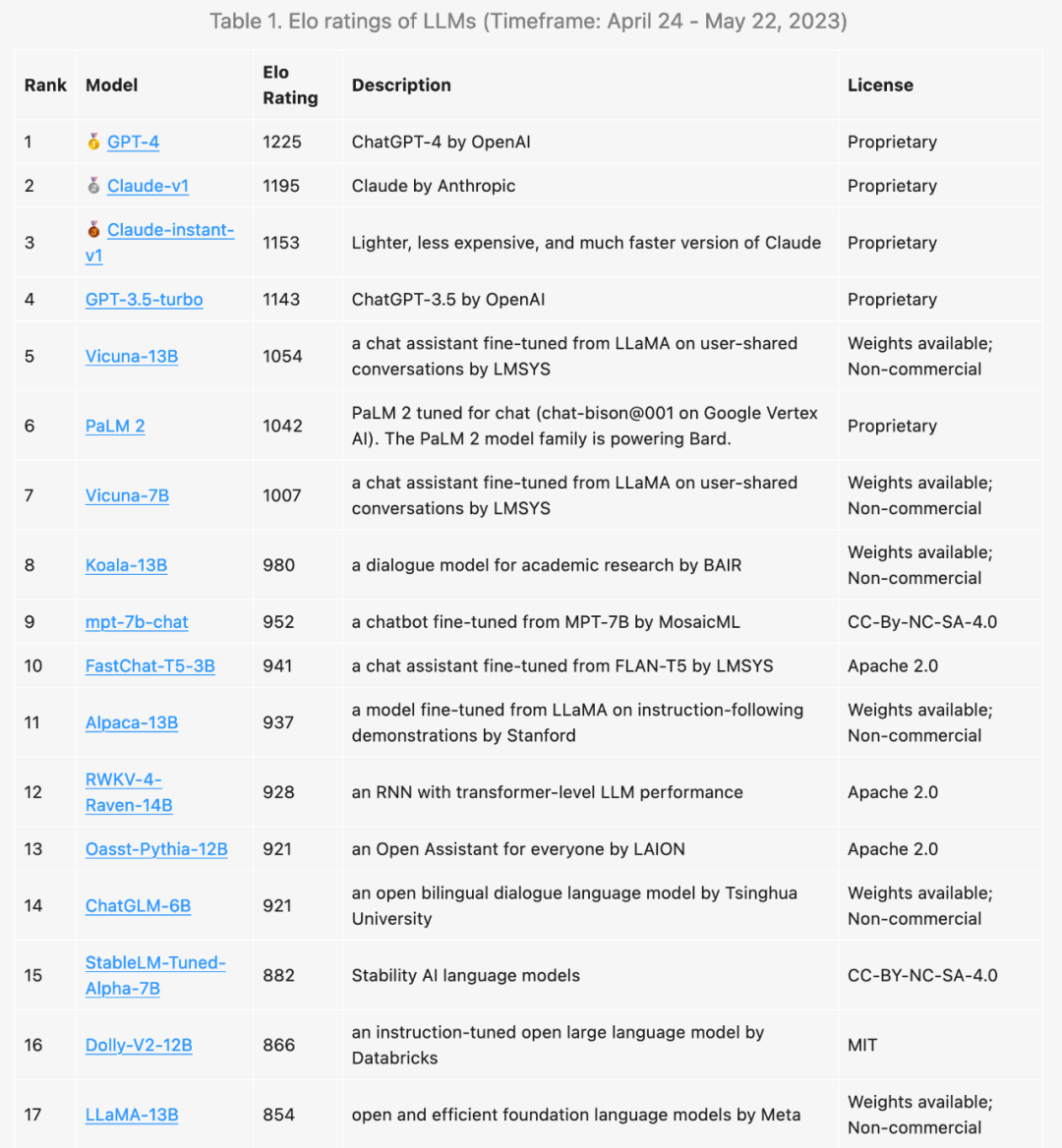
AlpacaEval 分为以 GPT-4 和 Claude 为元标注器的两个子榜单。
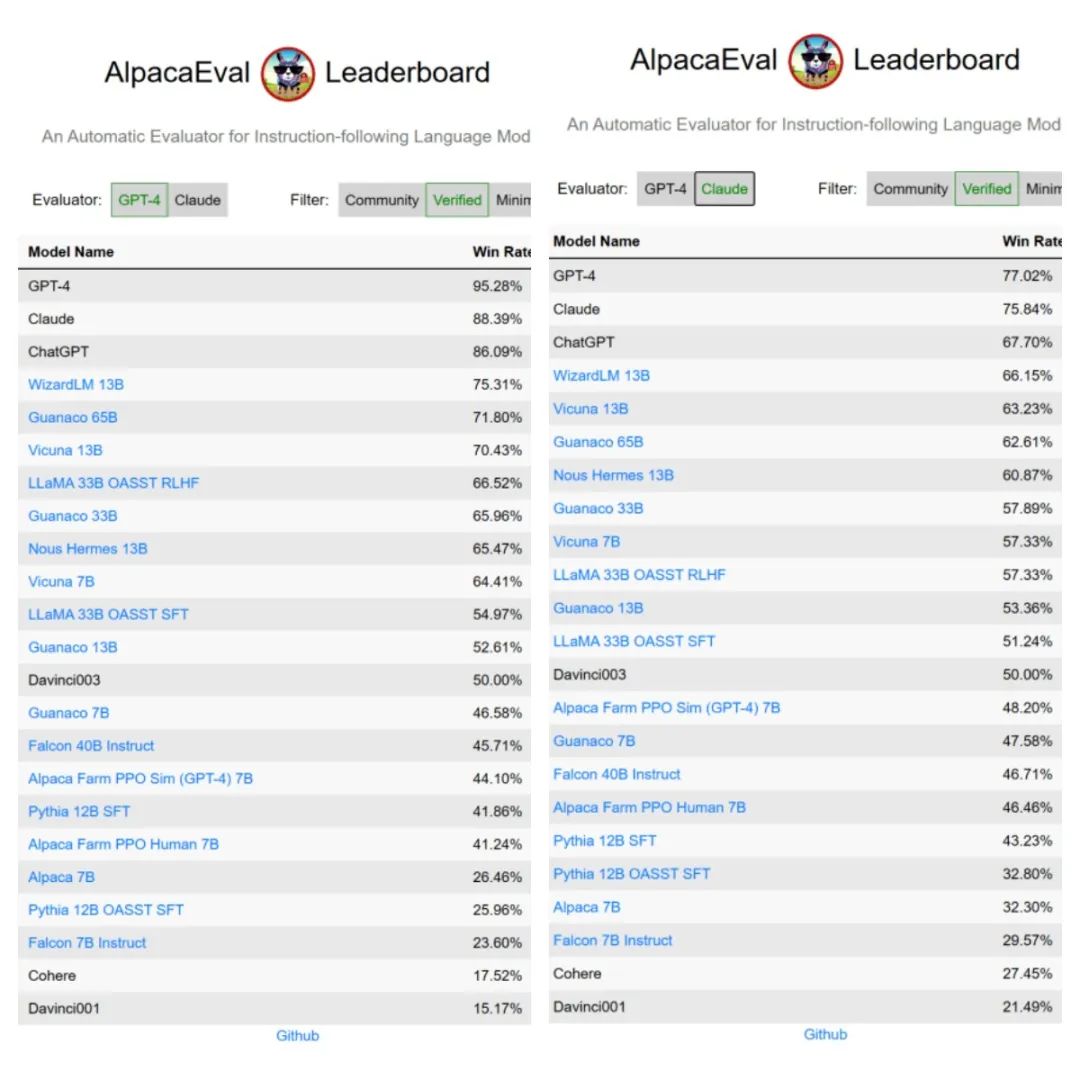 在斯坦福的这个 GPT-4 评估榜单中:
在斯坦福的这个 GPT-4 评估榜单中:
-
GPT-4 稳居第一,胜率超过了95%;胜率都在 80% 以上的 Claude 和 ChatGPT 分别排名第二和第三,其中 Claude 以不到 3% 的优势超越 ChatGPT。
-
值得关注的是,获得第四名的是一位排位赛新人——微软华人团队发布的 WizardLM。在所有开源模型中,WizardLM 以仅 130 亿的参数版本排名第一,击败了 650 亿参数量的 Guanaco。
-
而在开源模型中的佼佼者 Vicuna 发挥依然稳定,凭借着超过70%的胜率排在第六,胜率紧追 Guanaco 65B。
-
最近大火的 Falcon Instruct 40B 表现不佳,仅位居 12 名,略高于 Alpaca Farm 7B。
AlpacaEval 基于 AlpacaFarm 数据集来测试模型遵循一般用户指令的能力。具体地,研究人员以 GPT-4 或 Claude 为自动评估器,以 GPT-3.5(Davinci-003)为基准,将目标模型与 GPT-3.5 的回复进行比较。

论文地址:https://arxiv.org/pdf/2305.14387.pdf
项目地址:https://github.com/tatsu-lab/alpaca_farm/
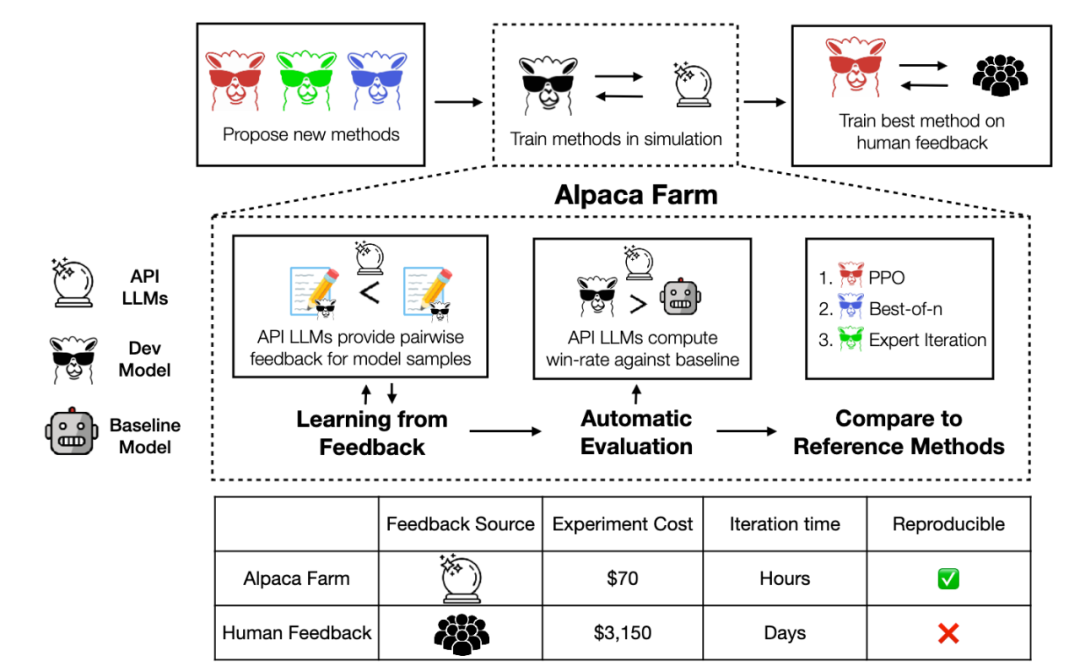
图注:AlpacaFarm是一个模拟沙盒,能够快速、廉价地对从人类反馈中学习的方法进行实验。它用API LLMs模拟人类反馈,提供一个经过验证的评估协议,并提供一套参考方法的实现。研究人员可以快速迭代模型开发,并将他们的方法转移到人类数据上进行训练,以最大限度地提高性能。虽然仅基于 GPT-4 进行自动评估,但与基于 1.8 万条真实人类标注排序结果之间高达 0.94 的皮尔逊相关系数,证明了 AlpacaEval 榜单排名的高可靠性。

那么相比其他的 LLM 自动评测器,如 alpaca_farm_greedy_gpt4、aviary_gpt4、lmsys_gpt4,还有人类(humans)评估,斯坦福的 AlpacaEval 评测器有什么特别?在 AlpacaEval set 上,斯坦福 AlpacaEval 团队通过与 2.5K 条人工标注结果(每个指令平均包含4个人工标注)对比,研究人员评估了不同的自动标注器的性能。对比结果显示,AlpacaEval 采用的 GPT-4 评测方式取得了最高的人类一致性,以及较低的误差,并仅需约 1/22 的人类标注成本。
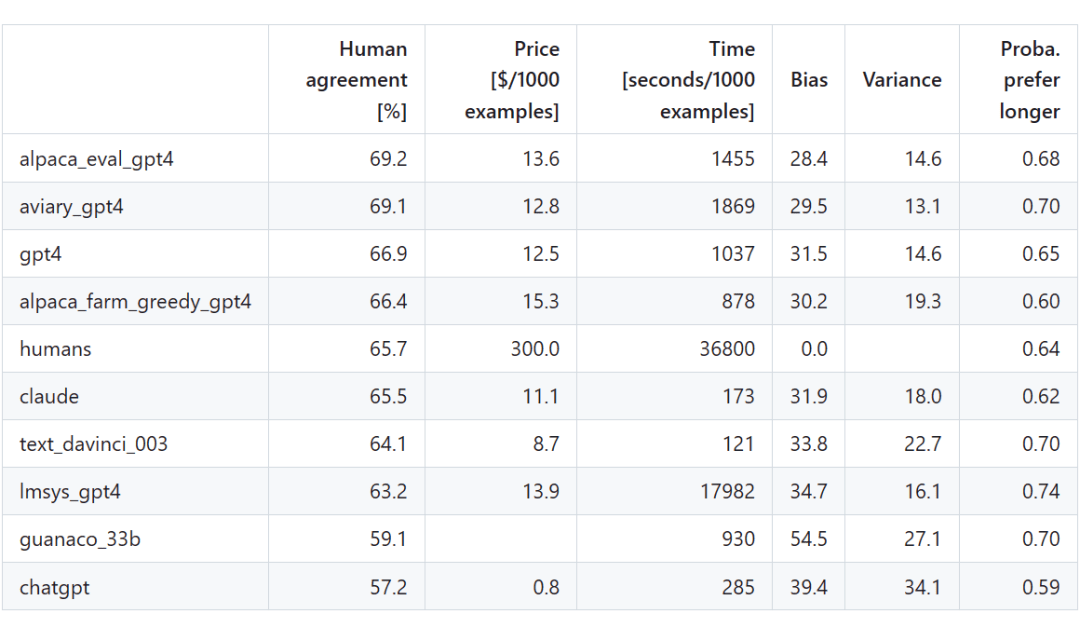
图注:人类一致性:标注者与交叉标注集中人类多数票之间的一致性。价格:每1000个标注的平均价格。时间:计算1000个标注所需的平均时间。相对于人工标注,全自动化的 AlpacaEval 仅需花费约 1/22 的经济成本和 1/25 的时间成本。
另外,还有一个关键问题:什么评估数据可以最好地区分模型。团队从统计角度出发,在 AlpacaEval 的所有子集上检验这个问题。下图显示了 AlpacaEval 每个子集的 80 个实例上每对模型的配对 t 检验的 p 值。例如,我们看到 Self-Instruct 数据集产生的统计能力最小,这表明可以从评估集中删除该数据集。
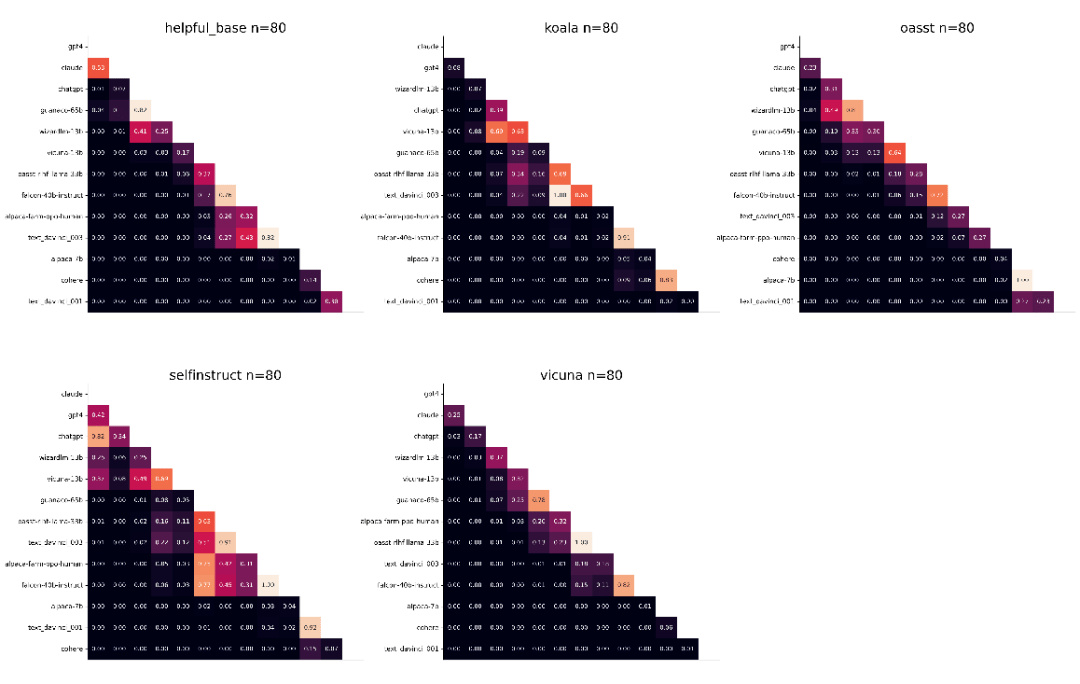
AlpacaEval 支持两种模式的模型评估方式:
- alpaca_eval:直接根据目标模型输出的响应来评估模型。
- alpaca_eval evaluate_from_model:根据 HuggingFace 已注册模型或这 API 提供商来端到端评测模型。
- 选择一个评估集,并计算指定为 model_outputs 的输出。默认情况下,我们使用来自 AlpacaEval 的 805 个示例。
import datasets
eval_set = datasets.load_dataset( "tatsu-lab/alpaca_eval", "alpaca_eval")[ "eval"]
for example in eval_set:
# generate here is a placeholder for your models generations
example["output"] = generate(example["instruction"])
-
计算 golden 输出 reference_outputs。默认情况下,在 AlpacaEval 上使用 text-davinci-003 的输出。
-
通过 annotators_config 选择指定的自动标注器,它将根据 model_outputs 和 reference_outputs 计算胜率。这里建议使用 alpaca_eval_gpt4 或 claude。根据不同的标注器,使用者还需要在环境配置中设定 API_KEY。
目前,AlpacaEval 团队已开源所有模型评估代码和分析数据,以及支持未来新模型榜单更新的测试工具。显然 AlpacaEval 对LLM模型评测来说很实用,但它仍不是一个全面的的模型能力评测系统,还有一些局限性:(1)指令比较简单;(2)评分时可能更偏向于风格而非事实;(3)没有衡量模型可能造成的危害。
WizadLM 作为 AlpacaEval 上表现最好的开源模型,让人十分好奇,它的强大来源是什么?WizardLM 是由 Can Xu 等人在 2023 年 4 月提出的一个能够根据复杂指令生成文本的大型语言模型。它使用了一个名为 Evol-Instruct 的算法来生成和改写指令数据,从而提高了指令的复杂度和多样性。 WizardLM 共有三个版本:7B、13B 和 30B。
论文链接:https://arxiv.org/abs/2304.12244代码链接:https://github.com/nlpxucan/WizardLM
WizardLM 的核心算法是指一种称为 Evol-Instruct 的指令进化论。与手动创建、收集、筛选高质量指令数据的巨大耗费不同,Evol-Instruct 是一种使用 LLM 而非人类创建大量不同复杂度级别的指令数据的高效途径。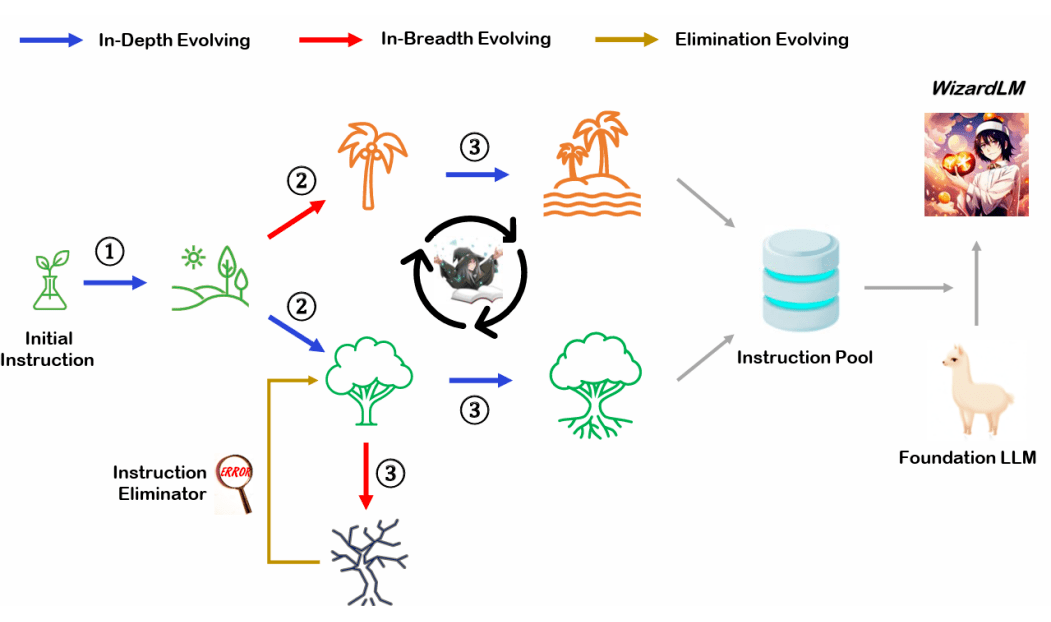
图注:Evol-Instruct 的指令进化论Evol-Instruct 算法从一个简单的初始指令开始, 然后随机选择深度进化或广度进化,前者将简单指令升级为更复杂的指令,而后者则在相关话题下创建新指令(以增加多样性)。以上两种进化操作是通过若干特定的 Prompt 提示 LLM 来实现。研究人员采用指令过滤器来筛选出失败的指令,这被称为淘汰进化。论文中,给出了4个重要的实验现象:
- 人类评估结果证明,由 Evol-Instruct 进化生成的机器指令质量整体优于人类指令(ShareGPT)。
- 高难度指令的处理能力:人类评估者认为此时 WizardLM 的响应比 ChatGPT 更受欢迎。
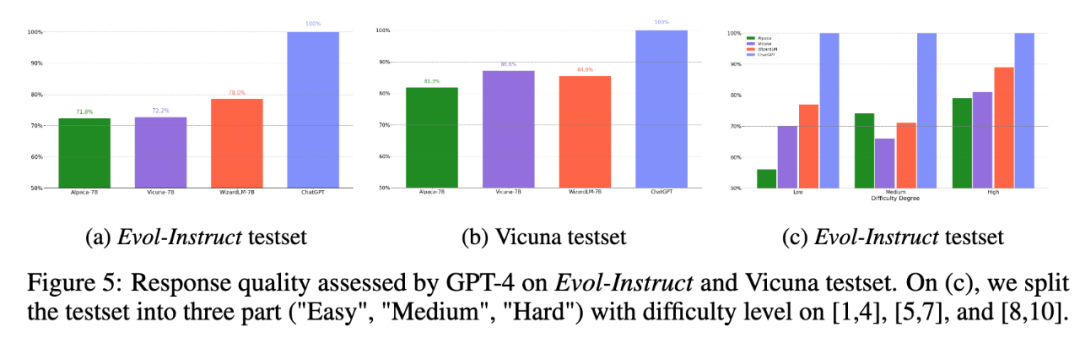
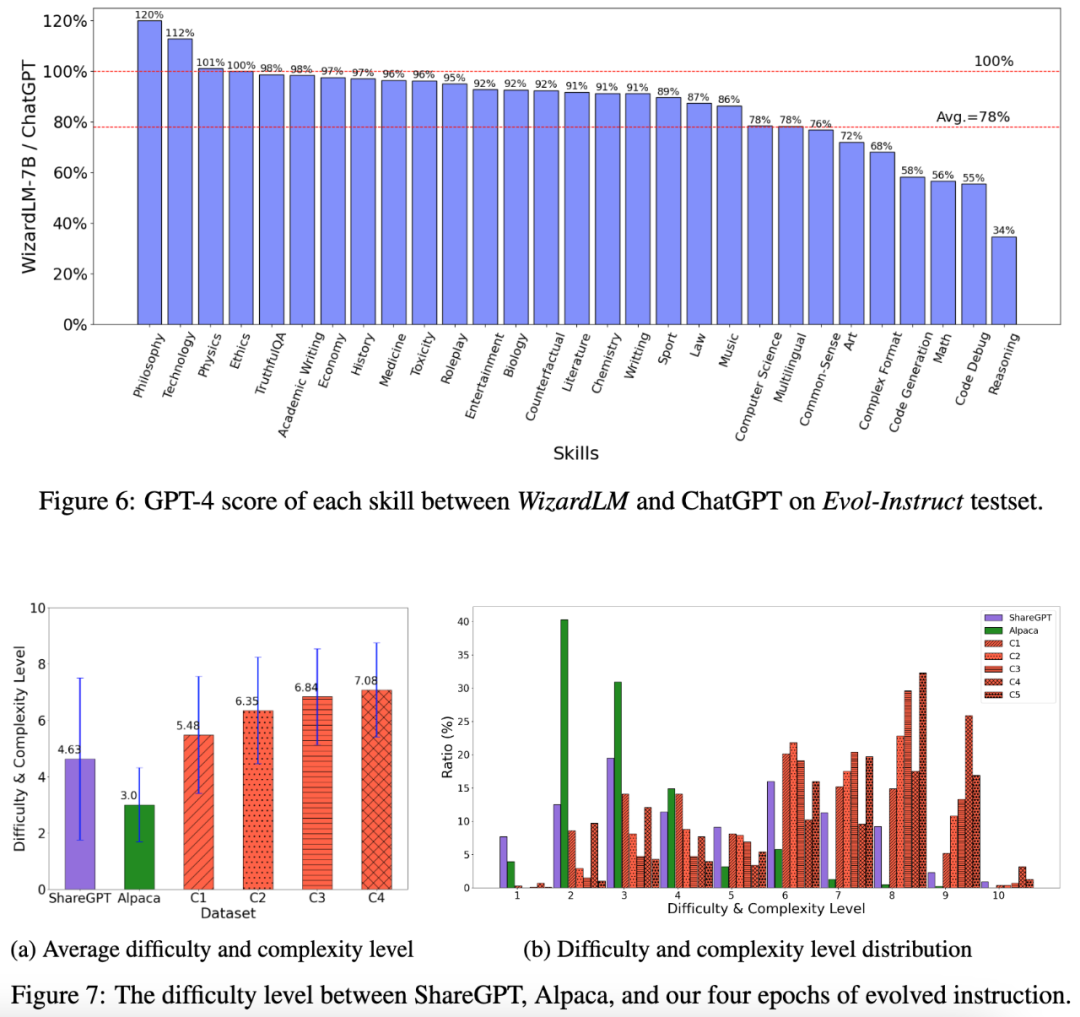
-
代码生成与补全能力:在 HumanEval 评估中,WizardLM-30B 同时击败了code-cushman-001 与目前最强代码开源模型 StarCoder 。这证明了 Llama 系列预训练模型的代码能力并不差,在高效的对齐算法加持下,依然可以获得优异的表现。
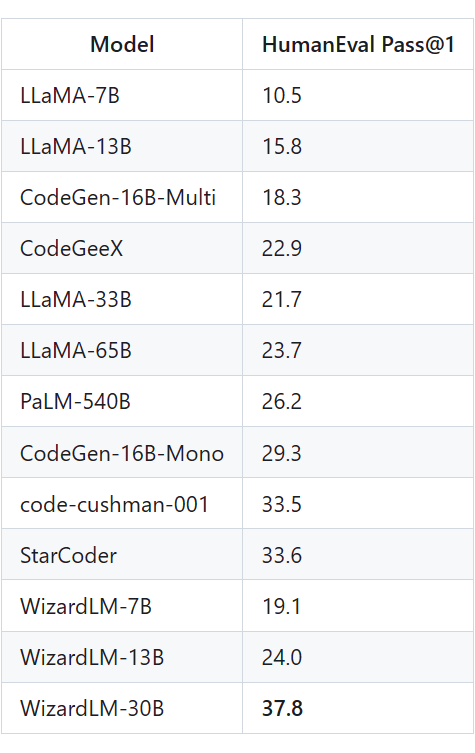
- WizardLM-13B 同时在 AlpacaEval 与 Evol-Instruct 测试集的 GPT-4 评估中,获得了高度一致的 ChatGPT 能力占比(前者为 87% ChatGPT,后者为 89% ChatGPT)。
最新发布的 WizardLM-30B,在 Evol-Instruct 测试集上取得了 97.8% 的 ChatGPT 分数占比,因此未来 30B 版本的 WizardLM 在 AlpacaEval 排行榜的表现应该很让人期待啊。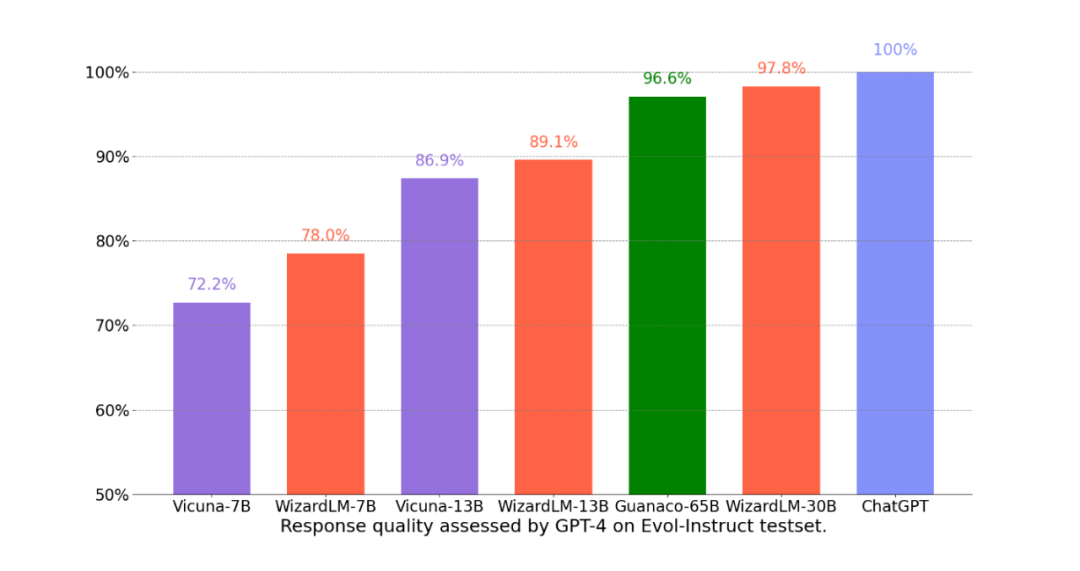
目前的大语言模型都是基于大量的开放域文本数据进行预训练和微调的,从而具有强大的通用性和适应性。大多数模型都具有某种嵌入式对齐(Alignment)方式,如LLaMA、Alpaca、Vicuna、WizardLM、ChatGLM等,目的就是为了防止模型做坏事,如生成一些违法违规的东西出来。按理说对齐是一件好事,它的初衷是敏感过滤,保证输出的合理性和合法性。但训练数据中不可避免的包含一些不合规的内容(如暴力、色情、歧视、谣言等),而大部分情况下敏感过滤都是人为操纵的,这就可能存在一定的倾向性或偏见。对于模型,可能损失一些有价值或有趣的信息,并限制模型的创造力和多样性。
例如可以观察到 ChatGPT 符合美国主流文化,遵守美国法律,并带有一定不可避免的偏见。在 HuggingFace 发布的开源LLM的排行榜中,可以看到13B的未对齐模型 Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基准测试上进行比较,甚至超越了65B的对齐模型。这就很微妙了,不对齐似乎也无不可取?作为面向公众的AI,拒绝回答有争议和包含潜在危险的问题,是必要的。但准确说,对于敏感问题的输出,用户具有所有权和控制权。
为了探索没有敏感过滤的语言模型的可能性和潜力,一个名为 faldore 的 Reddit 用户在 2023 年 5 月发布了一个新的语言模型:UNCENSORED WizardLM。这个模型是基于 WizardLM 的一个未经过滤的版本。根据 faldore 的介绍,他使用了 WizardLM 团队提供的原始训练脚本和未经过滤的数据集 ,在四块 A100 80GB 的显卡上训练了 36 小时和 60 小时,分别得到了 UNCENSORED WizardLM-7B 和 UNCENSORED WizardLM-13B 模型。
那么不走寻常路的不对齐模型 UNCENSORED WizardLM 真的好吗?UNCENSORED WizardLM 不会对输入或输出进行任何敏感过滤或审查,它会尽可能地按照指令生成文本,无论指令是否合理或合法。这意味着它可以生成一些其他模型无法或不愿生成的内容,如暴力、色情、歧视、谣言等。这种特点使得它具有更高的创造力和多样性,但也带来了更高的风险和责任。
参考:
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
https://lmsys.org/blog/2023-05-25-leaderboard/
AlpacaEval: https://tatsu-lab.github.io/alpaca_eval/
AlpacaFarm: https://crfm.stanford.edu/2023/05/22/alpaca-farm.html
WizardLM: https://github.com/nlpxucan/WizardLM
http://news.sohu.com/a/685451683_121119001
https://erichartford.com/uncensored-models
相关文章
