Generative AI for Programming Education: Benchmarking ChatGPT, GPT-4, and Human Tutors
T Phung, V Pădurean, J Cambronero, S Gulwani, T Kohn, R Majumdar, A Singla, G Soares
[MPI-SWS & Microsoft & TU Wien]
编程教育中的生成式人工智能:ChatGPT、GPT-4和人类导师的基准测试
要点:
-
动机:人工智能和大型语言模型在提升计算教育方面具有巨大的潜力,可以为初级编程提供下一代教育技术。然而,目前对这些模型在编程教育中的应用的研究还不够系统和全面。 -
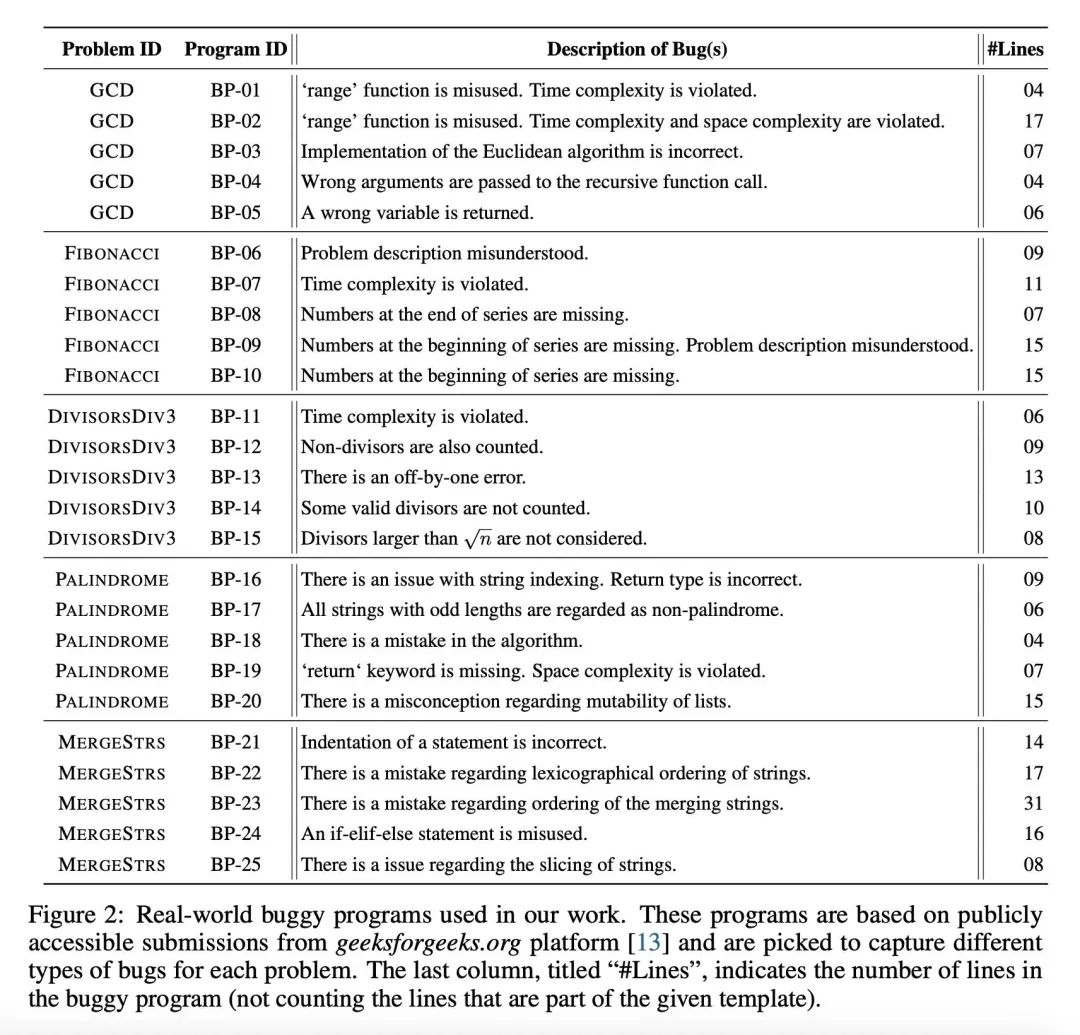
方法:系统地评估了两种模型,ChatGPT(基于GPT-3.5)和GPT-4,并将它们的性能与人类导师在多种编程教育场景下的表现进行了比较。评估使用了五个入门级Python编程问题和来自在线平台的真实世界错误程序,并使用基于专家的标注来评估性能。 -
优势:研究结果显示,GPT-4在多个场景中的表现显著优于基于GPT-3.5的ChatGPT,并接近人类导师的表现。这些结果也突出了GPT-4在某些设置中仍然存在的挑战,为未来开发技术以提高这些模型的性能提供了有趣的方向。
系统地评估了ChatGPT和GPT-4在编程教育中的应用,结果显示GPT-4在多个场景中的表现显著优于ChatGPT,并接近人类导师的表现。
https://arxiv.org/abs/2306.17156

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
