Reinforced Self-Training (ReST) for Language Modeling
C Gulcehre, T L Paine, S Srinivasan, K Konyushkova, L Weerts…
[Google DeepMind]
强化自训练(ReST)语言建模
-
提出一种称为Reinforced Self-Training(ReST)的新算法,用于使大规模语言模型与人类偏好保持一致。ReST使用离线强化学习,交替进行Grow步骤(模型生成新数据)和Improve步骤(在高奖励过滤数据上微调模型)。
-
与PPO等在线RL方法相比,ReST的样本和计算效率更高,因为训练数据是离线生成的,可以在多个Improve步骤中重复使用,似乎也比在线RL更少出现奖励欺骗的问题。
-
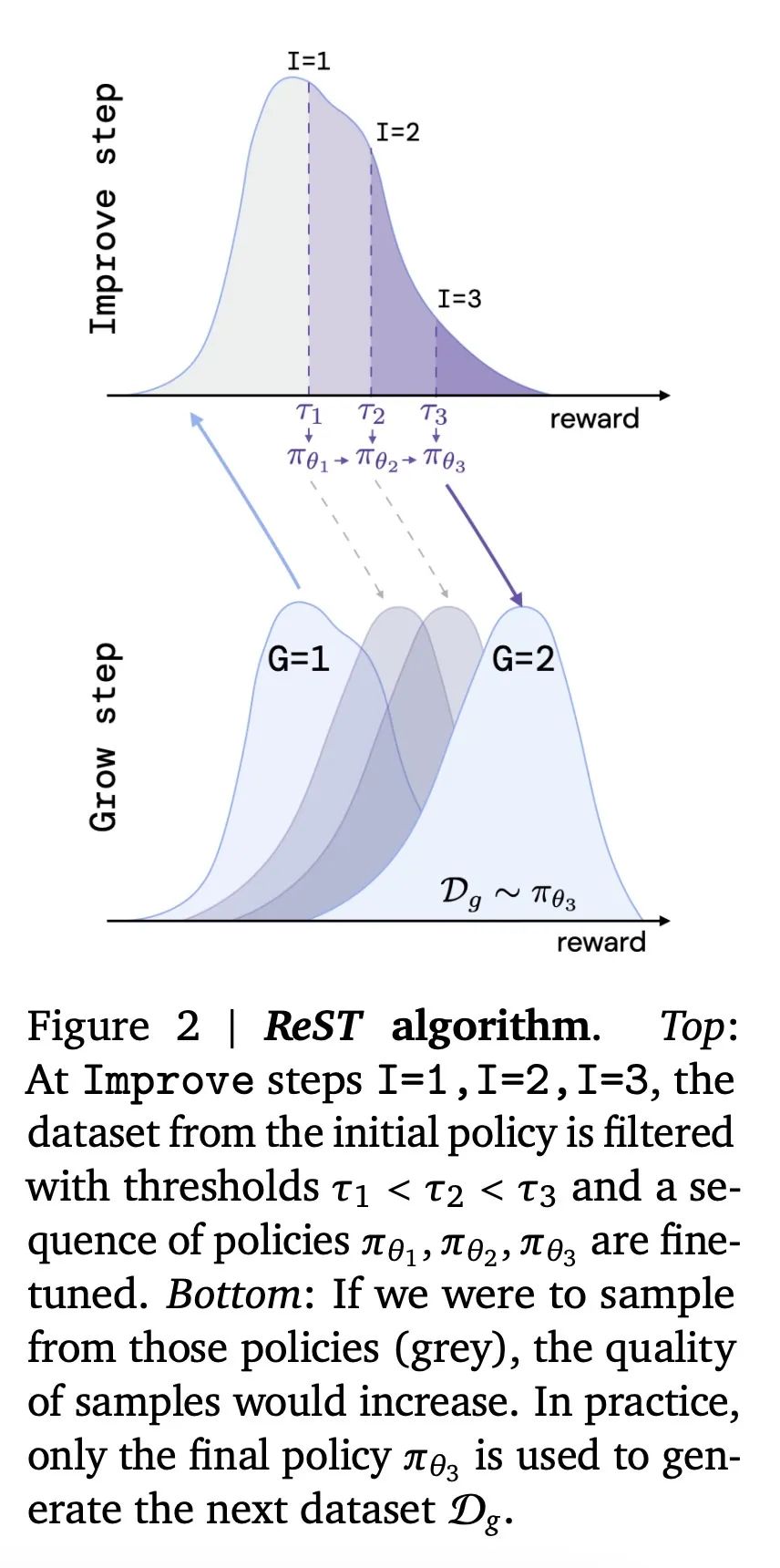
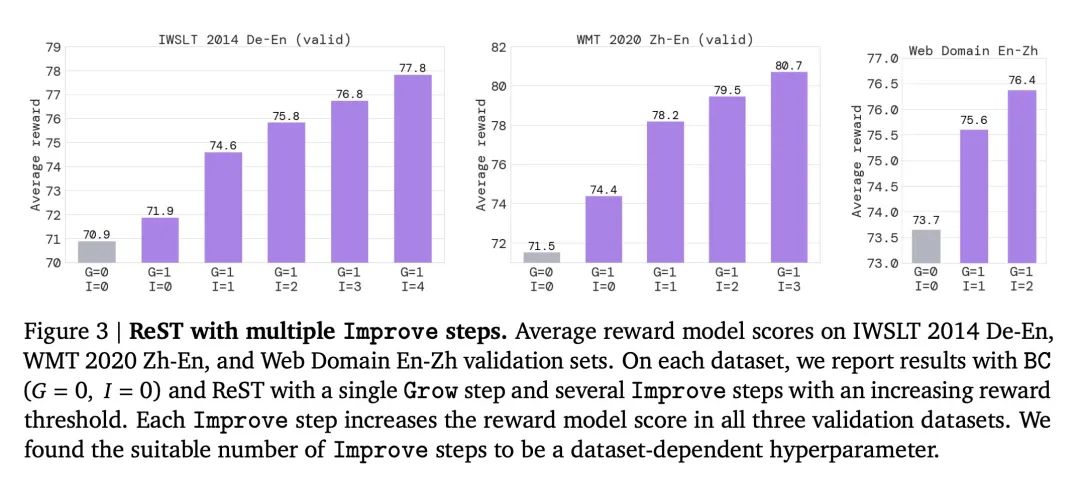
对于Improve步骤,简单的行为克隆(BC)损失优于更复杂的离线RL损失如V-MPO和GOLD,在优化奖励模型方面效果更好,关键是进行多次Improve步骤,并逐步提高奖励阈值。
-
虽然随着更多的Grow/Improve步骤,奖励模型得分持续上升,但人类评估分数在1次Grow步骤后达到峰值,表明奖励模型是人类偏好的不完美智能体。
-
在机器翻译任务上,ReST无论在自动化指标还是人工评估上,都明显优于监督学习,这种改进在多个数据集上都是一致的。
-
ReST的简单性、缺乏敏感超参数以及融合不同Grow/Improve算法的灵活性,使其成为一个有吸引力的算法,用于使大规模生成模型与人类偏好保持一致。
-
简单的BC损失优于离线RL,更高的奖励模型分数并不能直接转化为更好的人工偏好,更多的Grow步骤似乎会过拟合并降低人工评分。
动机:改进大型语言模型(LLM)的输出质量,使其更好地符合人类偏好,从而提高翻译质量并减少潜在的不安全内容。
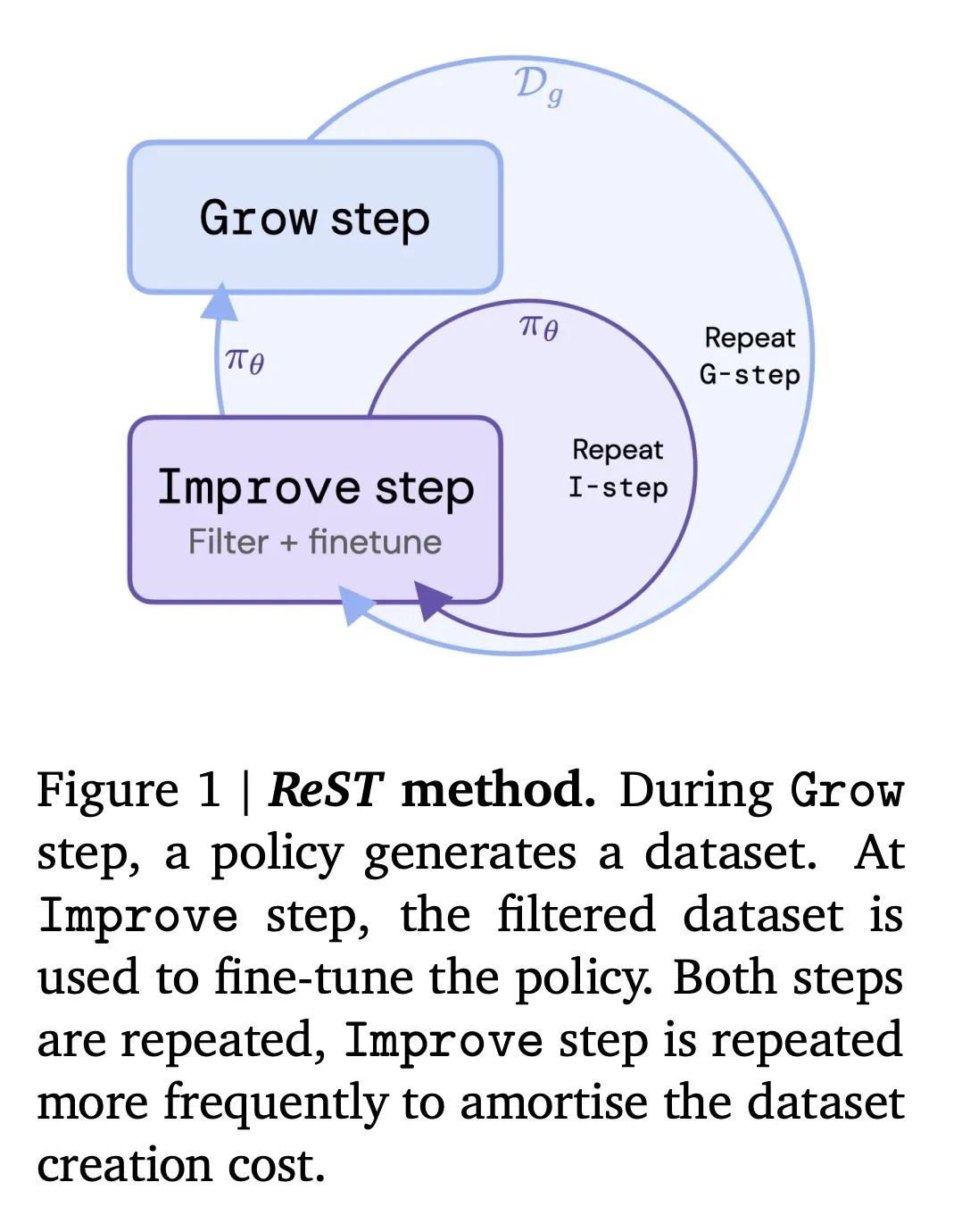
方法:提出一种名为“Reinforced Self-Training(ReST)”的算法,通过离线增强学习方法改进LLM策略。该算法包括两个循环:内循环(Improve)在固定的数据集上改进策略,外循环(Grow)通过从最新策略中采样来扩充数据集。ReST方法适用于所有生成学习任务,并重点应用于机器翻译。
优势:与在线方法相比,ReST方法具有更高的效率和可重复使用的训练数据集,减少了计算负担。此外,ReST方法简单稳定,调节的超参数较少。
提出一种名为ReST的算法,通过离线强化学习方法改进大型语言模型的翻译质量,以更好地符合人类偏好。
https://arxiv.org/abs/2308.08998
相关文章
