Probabilistic Inference in Reinforcement Learning Done Right
J Tarbouriech, T Lattimore, B O’Donoghue
[Google DeepMind]
-
本文对”强化学习作为推断”进行了原理性的贝叶斯处理,定义了状态-动作最优事件。 -
状态-动作最优概率P*兼顾了RL中的推断和控制。基于P*的策略可以高效地探索。 -
计算P*的确切值是不可行的,所以提出一个变分优化问题来逼近它,称为VAPOR。 -
VAPOR通过平衡乐观性和熵正则化来找到一个接近P*的占据措施,并有后悔保证。 -
通过扰动奖励增加高斯噪声,VAPOR可以推广到未知转移的情况。 -
汤普森采样和K学习被联系起来隐式地逼近P*,VAPOR提供了更直接的控制。 -
提出一个策略梯度方法VAPOR-lite将VAPOR扩展到深度强化学习,针对每个状态-动作单独调节熵正则化。 -
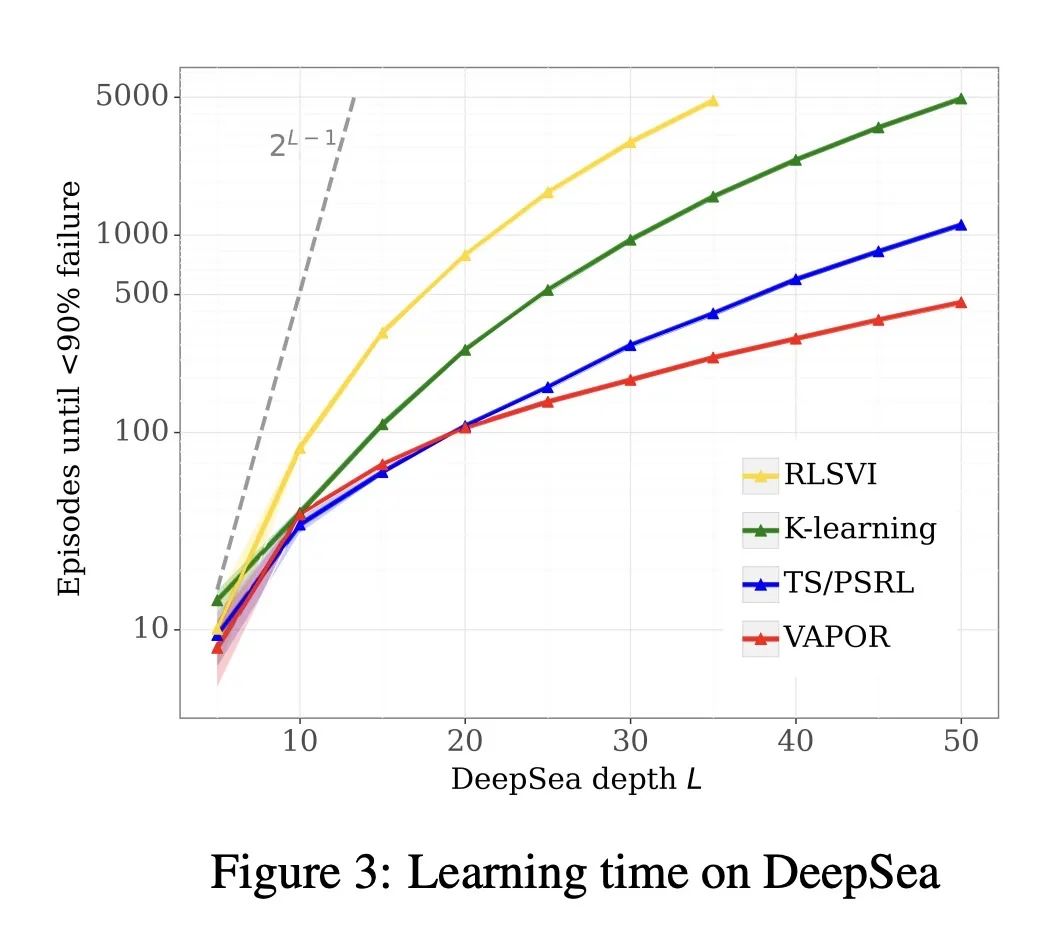
实验表明,VAPOR可以高效地求解难以探索的任务,如DeepSea。VAPOR-lite改善了Atari游戏的样本效率。
动机:传统的强化学习方法在处理复杂问题时可能无法准确地进行概率推理,导致性能下降。因此,需要进行严格的贝叶斯处理以提高强化学习的性能。
方法:提出一种新的贝叶斯近似方法,称为VAPOR,用于计算状态-动作对在最优策略下被访问的后验概率。通过解决该近似问题,可以生成一种有效的探索策略。
优势:VAPOR方法具有与Thompson采样、K-learning和最大熵探索等算法的强连接,并且在深度强化学习任务中表现出较好的性能优势。
提出一种基于贝叶斯处理的强化学习方法VAPOR,通过计算状态-动作对在最优策略下的后验概率来生成有效的探索策略,具有与其他算法的强连接。
https://arxiv.org/abs/2311.13294

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
