千模大战第三期
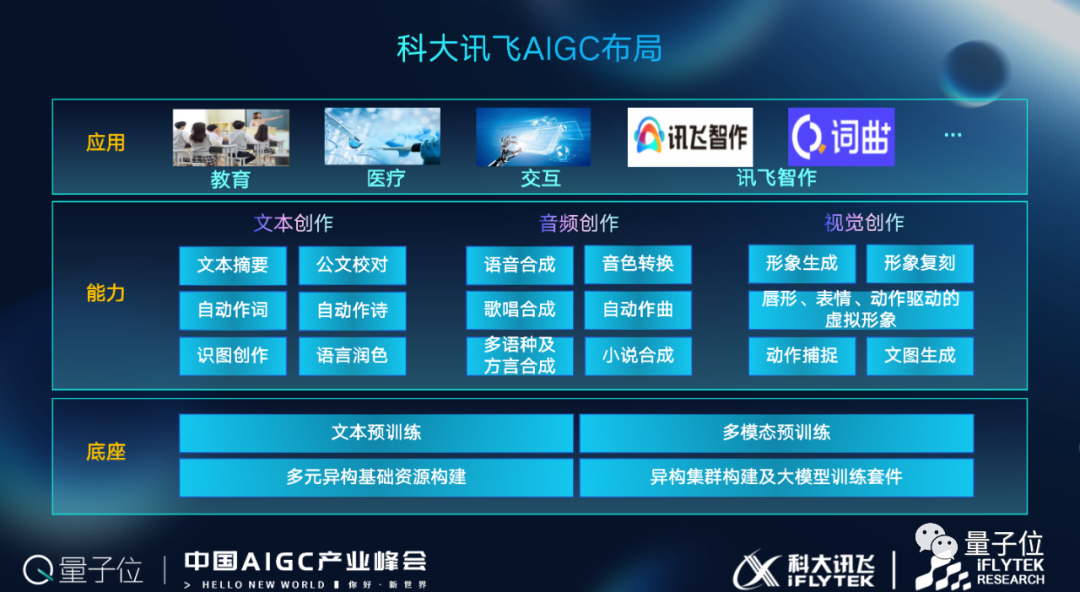
科大讯飞高建清:「底座+能力+应用」是科大讯飞AIGC整体布局的三层架构
文章来源:量子位
-
语音合成技术发展:科大讯飞拥有音频创作方面的全栈能力,致力于实现拟人化、情感化和口语化的语音合成。通过SMART-TTS系统,实现了多情感和多风格的语音合成,以满足不同场景需求。
-
虚拟人技术进步:科大讯飞在虚拟人多模态合成方面取得显著进步,从2D发展到3D虚拟人生成。通过语义驱动动作技术和语音可控的半身数字人像生成技术,提高了虚拟人动作的拟人度和契合度。
-
音频创作的未来方向:音频创作将侧重于大语言模型的应用,以改进声音特征控制,同时追求声音艺术,从简单表达发展到悦耳享受,融入音效和环境音。
-
AIGC技术在产品创新中的应用:科大讯飞利用音色创作技术推出AI虚拟歌手Luya,并结合全栈视觉生成能力,推出讯飞智作APP和讯飞音乐的词曲家平台,旨在打造音视频内容的AI创作基地,辅助创作者提高生产力。
博龙补一句:科大讯飞可能是最接近最早Google 某次发布会Demo里,打电话订餐厅场景的公司,从最大最全的语音通话数据库,到最强的语音合成能力,一应俱全,甚至可以围绕本地生活电话Booking这个场景,专门做个独立客户端,都不为过。
芯片暴涨,阿里百度,成英伟达打工仔
文章来源:中国企业杂志
-
GPU芯片需求暴增和价格上涨:随着中国科技公司和创业者竞相追逐大模型,GPU芯片需求量猛增,导致价格飙升。例如,英伟达A100芯片的单价在过去一年涨了超过50%,从约5万元涨到了近10万元。
-
国内大模型市场迅速扩张:除了阿里巴巴、百度等互联网巨头外,商汤科技、昆仑万维、毫末智行、360等公司也推出了大模型。据统计,中国年内推出的大模型数量已超过10个,未来可能需要8至20个大模型,甚至四五十个也说不定。
-
英伟达成为大赢家:在这一轮大模型创业潮中,英伟达成为了大赢家。2020年,全球跑AI的云计算与数据中心中,80.6%都在用英伟达的GPU驱动。英伟达股价翻倍,总市值达到6669亿美元,成为美国第五大上市公司。
-
中国AI企业面临的挑战:中国的科技巨头和创业者在追求AI技术的过程中面临着两个主要挑战。首先,由于美国的芯片禁令,他们无法获得最先进的芯片持续支持。其次,他们需要努力追赶国际上已经达到ChatGPT-4水平的技术。这使得中国企业在成本和竞争力上处于劣势。
-
算力市场的竞争和多元化:近期,阿里云和腾讯在算力市场上都有重大动作,试图通过降价、免费试用计划等策略提升市场份额。虽然英伟达在GPU市场占据主导地位,但未来算力需求的多元化和异构化将为其他厂商和创业公司提供更多的机会。最终,谁能在这个竞争激烈的市场中脱颖而出,将取决于谁能够拥有更强的战略定力和持续投入。
博龙补一句:文中印象最深的是黄仁勋准备把【卖芯片】改为【租芯片】,8块A100每月租金37000美金;感觉【租】的妙处也许在于,它可以实时竞价
真·从零复刻ChatGPT!斯坦福等开启「红睡衣」计划,先开源1.2万亿token训练集
文章来源:新智元
-
RedPajama计划:Ontocord.AI、苏黎世联邦理工学院DS3Lab、斯坦福CRFM、斯坦福Hazy Research和蒙特利尔学习算法研究所共同启动红睡衣计划,旨在生成可复现、完全开放、最先进的语言模型。
-
计划内容:红睡衣计划包括三部分:预训练数据集、基础模型和指令调优数据集与模型。
-
RedPajama-Data-1T开源:红睡衣计划的预训练数据集RedPajama-Data-1T已开源,包含七个子集,数据预处理相关脚本已开源。
-
训练进度:开发团队在橡树岭领导计算设施(OLCF)的支持下开始训练模型,预计几周后开源。
-
复刻LLaMA:LLaMA是一组基础语言模型,参数范围从70亿到650亿不等,使用公开数据集达到SOTA水平,数据集和预处理操作详细描述。
博龙补一句:从零开始训练才是真正的开源,第一适用的是某些小语种文化的大模型,如果只是English CommonCrawl、GitHub、维基百科这类数据源,多样化的文化表达很容易被淹没
不想被白嫖了,Reddit 将向 OpenAI 、谷歌等公司收取 API 费用,后者一直免费用其聊天内容训练大模型
文章来源:AI前线
-
向付费专区转变:Reddit计划将AI聊天机器人所依赖的数据资源向付费专区转变,从而实现获利。
-
部分用例仍免费:Reddit计划对某些用例保持API免费,例如构建审核工具或在教育和研究环境中使用Reddit的用户。
-
商业用途需签订单独协议:Reddit新条款要求商业用途,如培训法学硕士等,与Reddit签订单独协议,而不是直接授予开发者许可。
博龙补一句:数据源终于开始抽税了——国内的优质公域数据源知乎也最应该干这些事,反过来想,国内最优质的私域数据源微信,也应该把私人的聊天记录API化给每一位个人用户,让大家都能训练属于自己的私域模型,微信既收了一道税,也不违背自己的产品哲学,还收获了掌声;不然人人都重复Daily0408.3那样的过程,也太过痛苦了
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
