Cell2Sentence: Teaching Large Language Models the Language of Biology
D Levine, S A Rizvi, S Lvy, N Pallikkavaliyaveetil…
[Yale University]
Cell2Sentence:教大型自然语言模型掌握生物学语言
要点:
-
本文提出Cell2Sentence,一种将单细胞基因表达数据表示为文本序列的方法,称为“细胞句子”,可将自然语言处理模型应用于转录组学。 -
细胞句子由每个细胞中基因按表达水平排序的基因名组成,这个排名转换保留了原始基因表达数据中的大部分信息。 -
细胞句子可以用于微调预训练的语言模型,如GPT-2。以这种方式微调过的模型在给定提示的条件下可以生成逼真的细胞类型。 -
与仅在细胞句子上训练相比,语言模型预训练可以提高细胞句子任务上的性能,模型可以生成、分类和恢复细胞的表达。 -
Cell2Sentence提供了一个简单的框架,使用现有的库(如HuggingFace Transformers)将语言模型适配到转录组学。它以模块化的方式在数据和细胞句子之间进行转换。 -
在细胞句子上微调的模型与scVI等基线相比,生成和区分细胞类型的能力有所提高,自回归预测也从语言预训练中受益。 -
潜在的应用包括生成细胞、识别标记、通过自然语言解释数据以及建模基因表达对扰动的影响。
动机:将大型语言模型应用于生物学领域,特别是单细胞转录组学,以便分析、解释和生成单细胞RNA测序数据。
方法:通过一种称为Cell2Sentence(C2S)的方法,将单细胞的基因表达数据表示为基因名的文本序列,通过表达水平进行排序。然后,使用预训练的语言模型如GPT-2对这些基因序列进行微调。
优势:通过自然语言预训练和C2S训练,模型在转录组任务上的性能显著提高。经过微调的模型可以根据基因序列生成生物学上有效的细胞,也可以根据细胞句子准确预测细胞类型标签。这表明使用Cell2Sentence进行微调的语言模型可以对单细胞数据进行生物学理解,同时保持生成文本的能力。
提出一种将单细胞转录组数据表示为文本序列,并使用预训练的语言模型进行微调的方法,从而使模型能够生成和解释单细胞数据,实现自然语言交互。
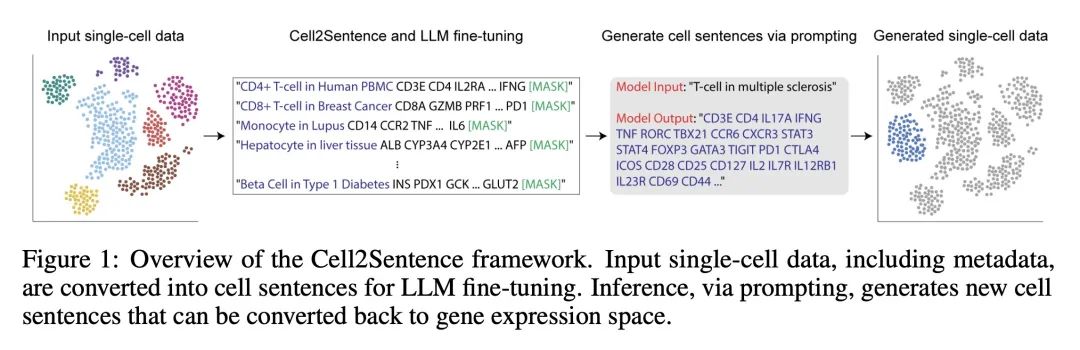
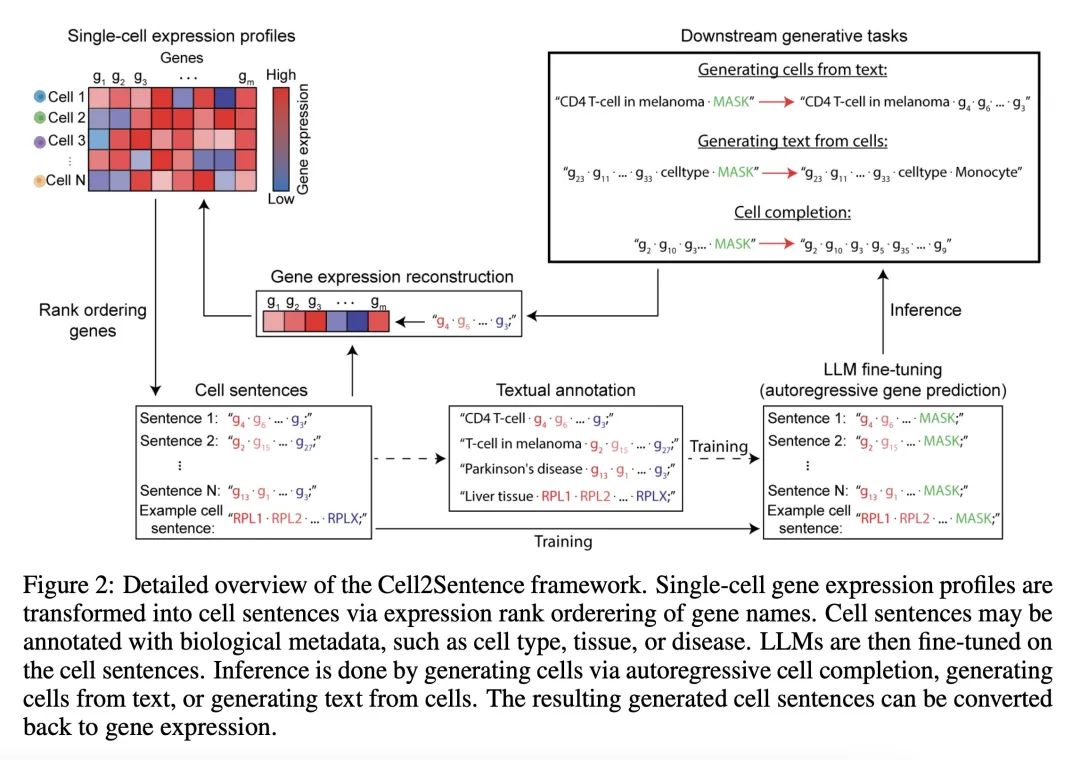
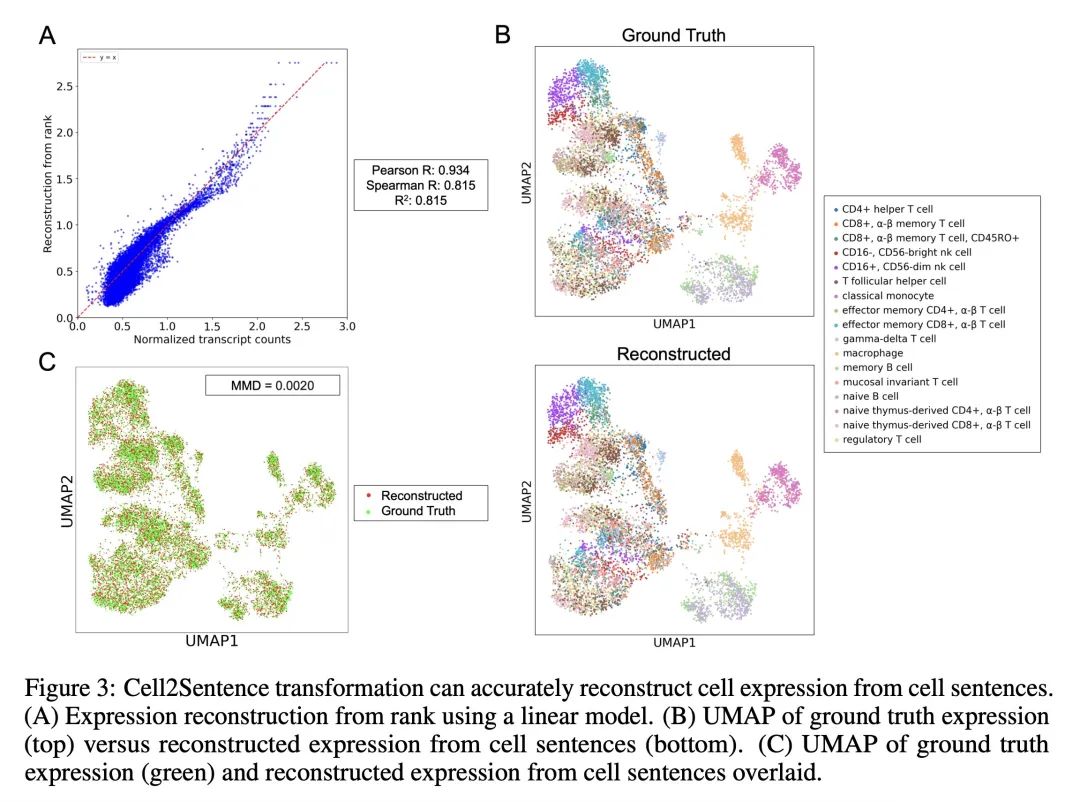
Large language models like GPT have shown impressive performance on natural language tasks. Here, we present a novel method to directly adapt these pretrained models to a biological context, specifically single-cell transcriptomics, by representing gene expression data as text. Our Cell2Sentence approach converts each cell’s gene expression profile into a sequence of gene names ordered by expression level. We show that these gene sequences, which we term “cell sentences”, can be used to fine-tune causal language models like GPT-2. Critically, we find that natural language pretraining boosts model performance on cell sentence tasks. When fine-tuned on cell sentences, GPT-2 generates biologically valid cells when prompted with a cell type. Conversely, it can also accurately predict cell type labels when prompted with cell sentences. This demonstrates that language models fine-tuned using Cell2Sentence can gain a biological understanding of single-cell data, while retaining their ability to generate text. Our approach provides a simple, adaptable framework to combine natural language and transcriptomics using existing models and libraries. Our code is available at: https://github.com/vandijklab/cell2sentence-ft.
https://www.biorxiv.org/content/10.1101/2023.09.11.557287v1
相关文章
