LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
Y Chen, S Qian, H Tang, X Lai, Z Liu, S Han, J Jia
[CUHK & MIT]
LongLoRA:长上下文大语言模型的高效微调
要点:
-
论文提出LongLoRA,这是一种高效地扩展预训练大语言模型(LLM)如LLaMA2的上下文长度的方法,计算成本有限。 -
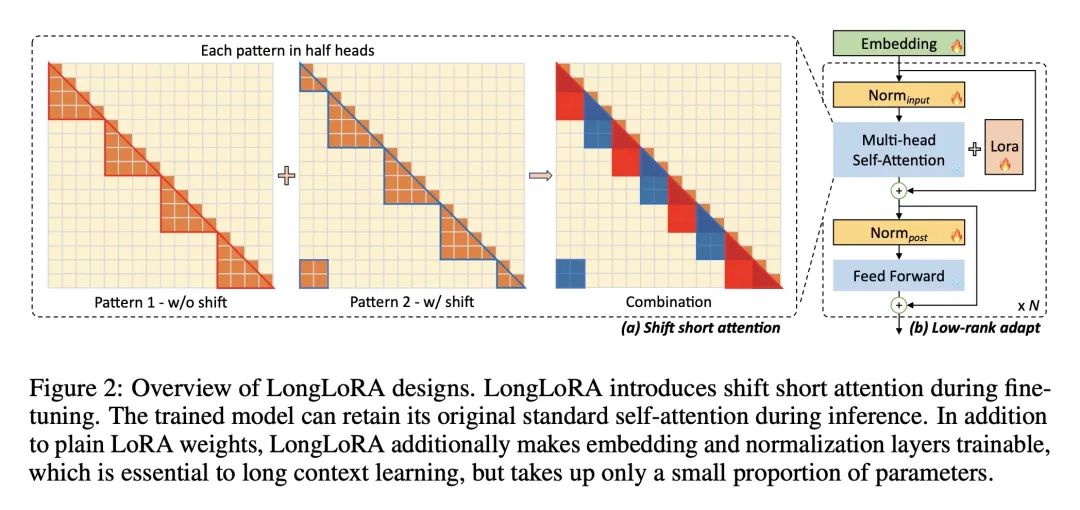
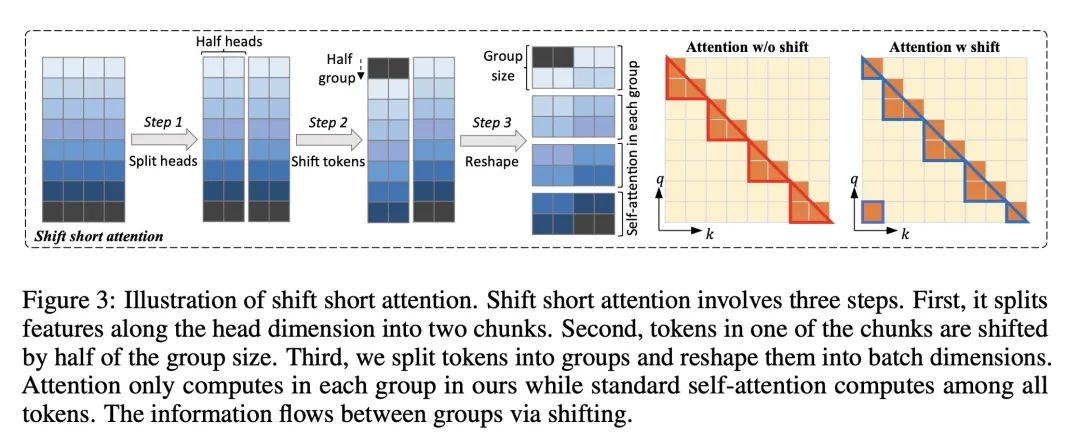
LongLoRA在微调过程中使用移位短注意力(S2-Attn)来逼近完整的注意力,减少了标准自注意力的二次复杂性,模型在推理时保留原始的注意力架构。 -
LongLoRA还通过使嵌入和归一化层可训练来改进LoRA训练,这对长上下文学习至关重要,但只占很小的参数量。 -
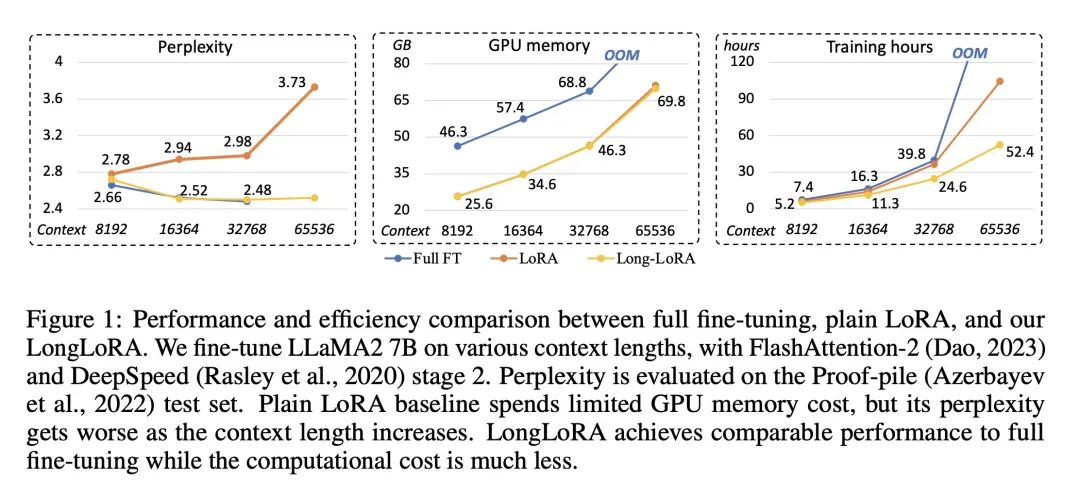
实验表明,LongLoRA可以在单个8x A100机器上,高效地将LLaMA2模型从4k扩展到100k上下文长度(7B),最多可达32k(70B)。 -
LongLoRA实现了与完整微调和完整注意力相当的效果,但计算成本要低得多,与FlashAttention-2等技术兼容。 -
收集了包含3k+长上下文问题答对的LongQA数据集,用于监督微调以提高聊天能力。
动机:传统的大语言模型(LLM)训练需要耗费大量的计算资源和时间,限制了其在长上下文任务中的应用。因此,本文旨在提出一种高效的微调方法来扩展预训练LLM的上下文大小,以降低计算成本。
方法:提出LongLoRA方法,通过两个方面来加速LLM的上下文扩展。首先,使用稀疏的局部注意力机制来进行微调,将上下文扩展的计算成本降低到与原始注意力机制相似的水平。其次,重新设计参数高效的微调策略,通过可训练的嵌入和归一化层来实现上下文扩展。具体地,引入了shift short attention(S2-Attn)方法,将上下文分成多个组,并在每个组中进行注意力计算,同时通过移位操作在不同组之间传递信息。
优势:LongLoRA方法在保持模型原始架构的同时扩展了上下文大小,且与现有技术兼容。论文通过实验证明了LongLoRA的有效性和高效性,达到了与全微调相当的性能,但计算成本大大降低。
提出一种高效的微调方法LongLoRA,通过稀疏局部注意力和参数高效微调策略实现了大语言模型的上下文扩展,有效降低了计算成本。
https://arxiv.org/abs/2309.12307
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
