Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
解决问题:这篇论文旨在解决使用大型语言模型(LLMs)进行实际应用所面临的内存效率和计算效率问题。论文提出了一种新的机制,旨在通过利用更少的训练数据来训练比LLMs更小的模型,并且在性能上超越LLMs。
关键思路:
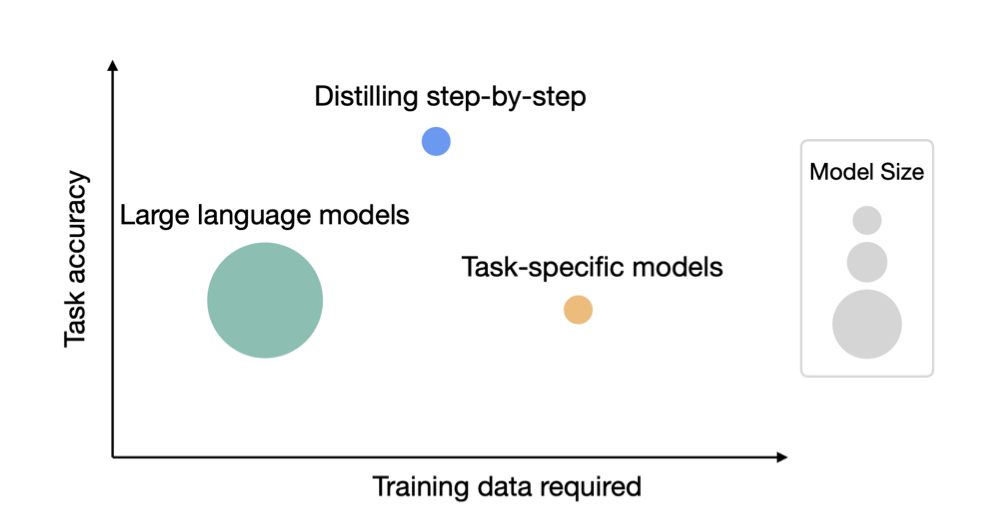
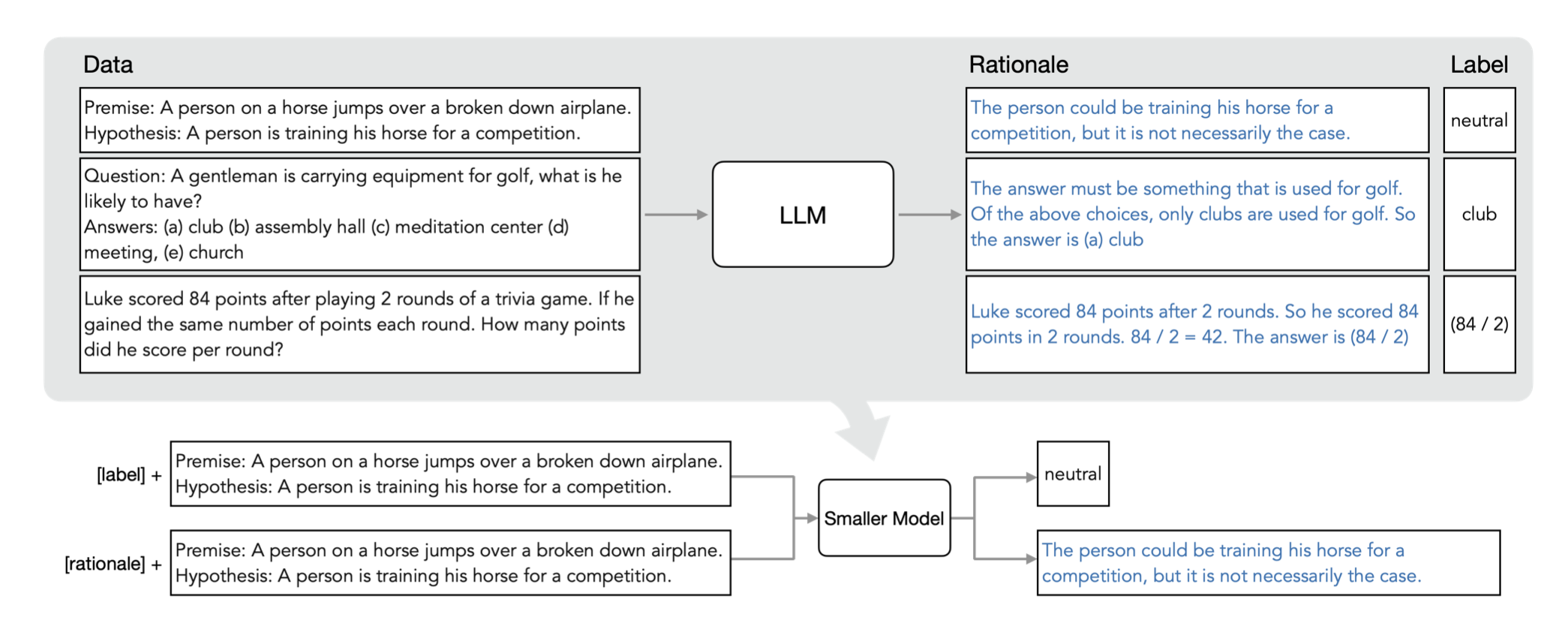
Distilling step-by-step是一种新的机制,它在多任务训练框架内利用LLM原理作为小模型的额外监督来训练更小的模型。与微调和蒸馏相比,该机制使用更少的标记/未标记训练示例实现更好的性能。与LLMs相比,我们使用更小的模型尺寸实现更好的性能。同时,我们还减少了超越LLMs所需的模型大小和数据量,例如在一个基准任务上,我们的770M t5模型仅使用80%的可用数据就能超越540B PaLM模型。
其他亮点:
论文的实验设计了4个NLP基准测试,并展示了Distilling step-by-step的三个发现。此外,该论文还提出了一种新的机制,可以在使用更少的训练数据的情况下训练出比LLMs更小的模型,并且在性能上超越LLMs。
关于作者:
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, Tomas Pfister
University of Washington、Google Cloud AI Research、Google Research
论文摘要:
这篇文章介绍了一种名为“Distilling step-by-step”的新机制,可以通过在多任务训练框架中提取大型语言模型(LLM)的理性作为小模型的额外监督,从而训练出优于LLM的小模型,并且所需的标注/未标注训练样本数量比微调或蒸馏少得多。研究人员通常通过微调或使用LLM生成的标签进行蒸馏来训练更小的任务特定模型,但是这些方法需要大量的训练数据才能达到与LLM相当的性能。
在4个自然语言处理基准测试中,作者发现,相比于微调和蒸馏,他们的机制使用更少的标注/未标注训练样本就能够取得更好的性能。相比于LLM,他们使用更小的模型大小就能取得更好的性能。他们还减少了超过LLM所需的模型大小和数据量,例如在一个基准任务上,他们的770M T5模型仅使用了80%的可用数据就优于540B PaLM模型。
相关文章
