

01 作者信息
02 论文简介
03 研究设计
-
第一阶段
固定视觉预训练模型,通过三个任务来训练一个 Q-Former 将图像输入中的语义编码到一个和文本特征空间相似的特征空间中。具体来讲,模型基于 K 个可学习的 query 嵌入和 cross-attention 机制从图像中获取特征,三个任务包括:
-
1. 图文匹配:对输入的(图像,文本)二元组分类,判断其是否相关
-
2. 基于图像的文本生成:给定图像输入,生成对应的文本描述
-
3. 图文对比学习:拉近图像特征和对应文本特征的距离,增大其和无关文本特征的距离
-
第二阶段
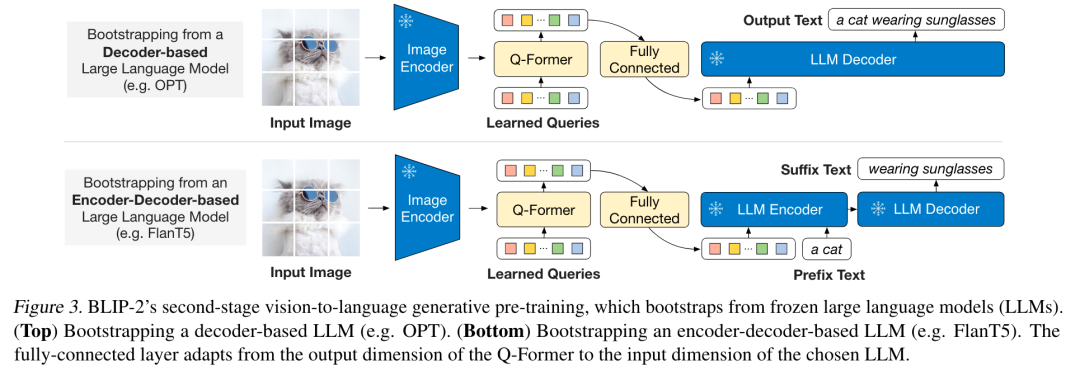
04 实验结果
BLIP-2 仅仅通过训练轻量的 Q-Former 和一个很小的全连接网络,便可以在零样本的 VQA 任务或是零样本的 Image Captioning 任务上实现 SoTA (state-of-the-art)的性能。
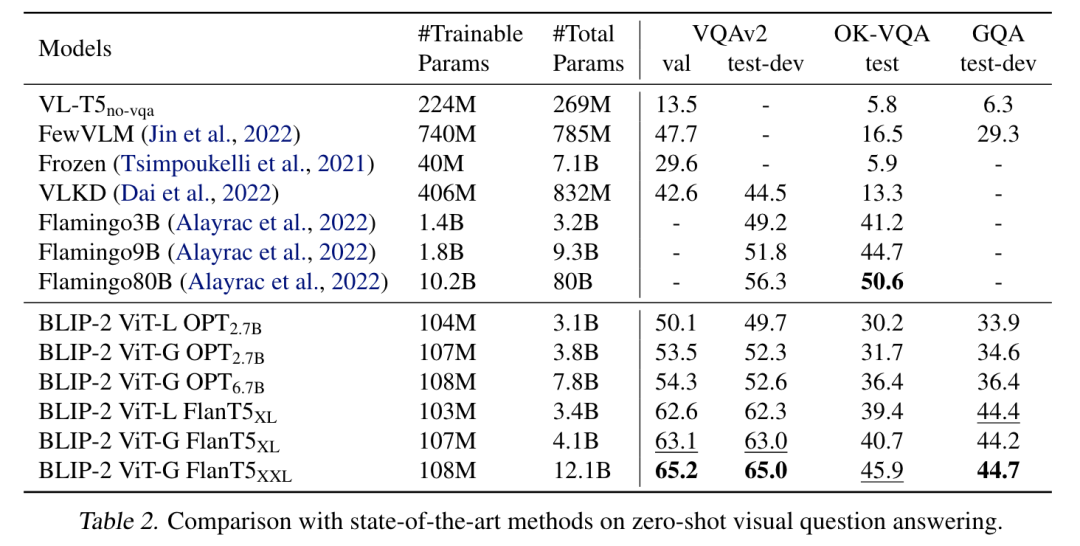

在微调的场景下(例如 QA 任务)也能够取得不错的性能,相比一些更大的模型, BLIP-2 能够以更少的可训练参数取得更好的性能。

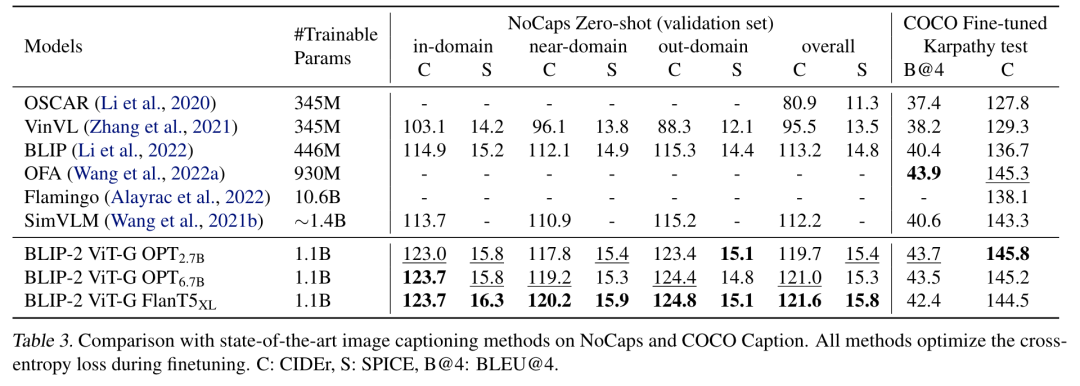
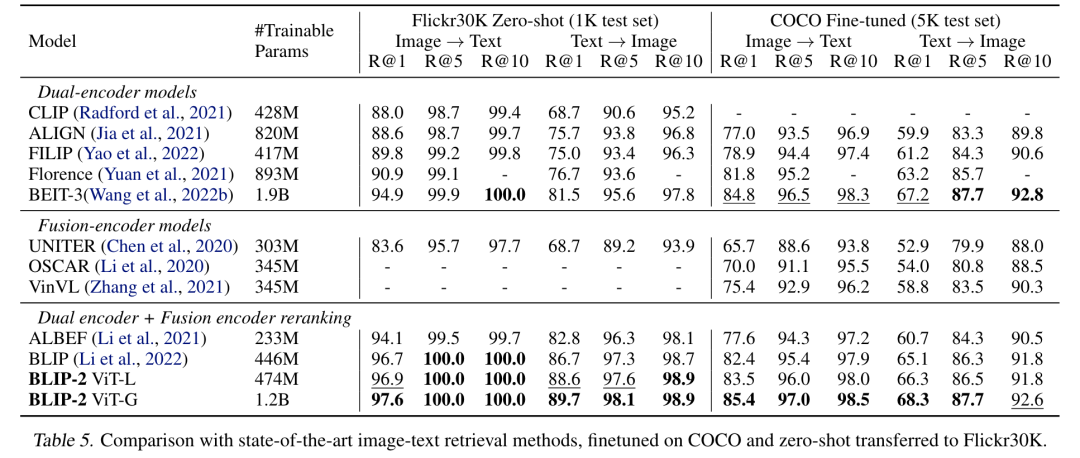
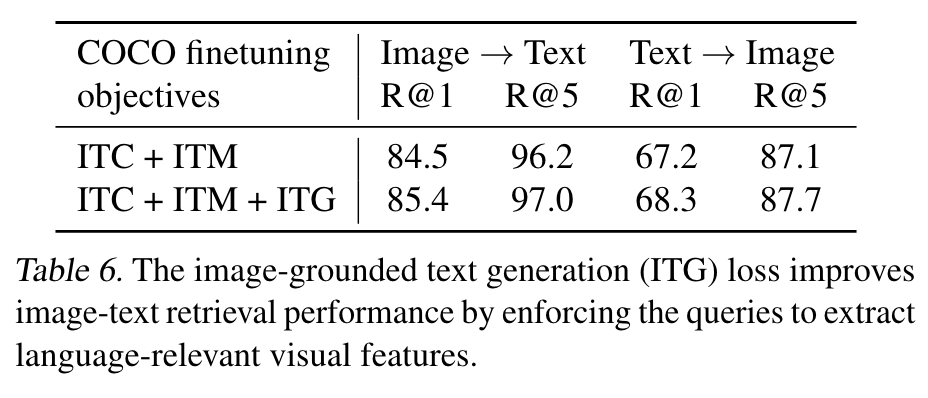
进行第一阶段的微调/训练之后,模型能够在下游任务上有更好的表现

05 论文贡献
优点

缺点
-
模型没有多模态的 In-Context-Learning 能力
-
保留了大语言模型的一些缺点,比如可能输出不准确的信息

我们为读者准备了一份高清思维导图,包括了论文中的重点亮点以及直观的示意图。点击下方名片 关注 OpenBMB ,后台发送“论文速读” ,即可领取论文学习高清思维导图和 FreeMind !
➤ 加社群/ 提建议/ 有疑问




© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
