Evaluating ChatGPT’s Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness

解决问题:
本文聚焦于ChatGPT在各种信息抽取任务上的系统性评测。针对于7个细粒度信息抽取任务和14个数据集,从模型性能、可解释性、校准度和忠实度这四个角度,设计了15个指标(10个从ChatGPT自动获取的指标,5个领域专家标注的指标),对ChatGPT进行了全面评估。实验结果表明,ChatGPT在标准IE设置下,性能与有监督模型有很大差距。但是,ChatGPT在OpenIE的场景下输出非常符合人类预期。同时,通过领域专家标注表明,ChatGPT可以对自己的预测结果给出可靠的解释,这表明ChatGPT有极强的解释能力。但是ChatGPT会对自己的预测过度自信,给出非常高的预测置信度,从而导致较低的校准度。最后,本文还验证了ChatGPT的决策非常忠实于原文,即不会通过虚构来解决或者解释问题。本文说明,ChatGPT在信息抽取领域仍然有很多的改进角度和提升空间。
其他亮点:
本文通过ChatGPT对7个细粒度信息抽取任务共14个数据集进行了性能测试和系统评估,并发布了代码和标注数据集,以进一步推动相关研究。值得注意的是,本文发现ChatGPT在标准信息抽取设置下表现欠佳,而OpenIE设置下表现出色,并且对自己的预测结果具有很强的可解释性和对输入原文的忠实度,然而会出现预测过度自信的问题。这些结论都为信息抽取领域提供了新的研究思路。
关于作者:
Bo Li, Gexiang Fang, Yang Yang, Quansen Wang, Wei Ye, Wen Zhao, Shikun Zhang
北京大学知识计算实验室(KCL)
项目信息:
https://github.com/pkuserc/ChatGPT_for_IE
文章链接:https://arxiv.org/abs/2304.11633
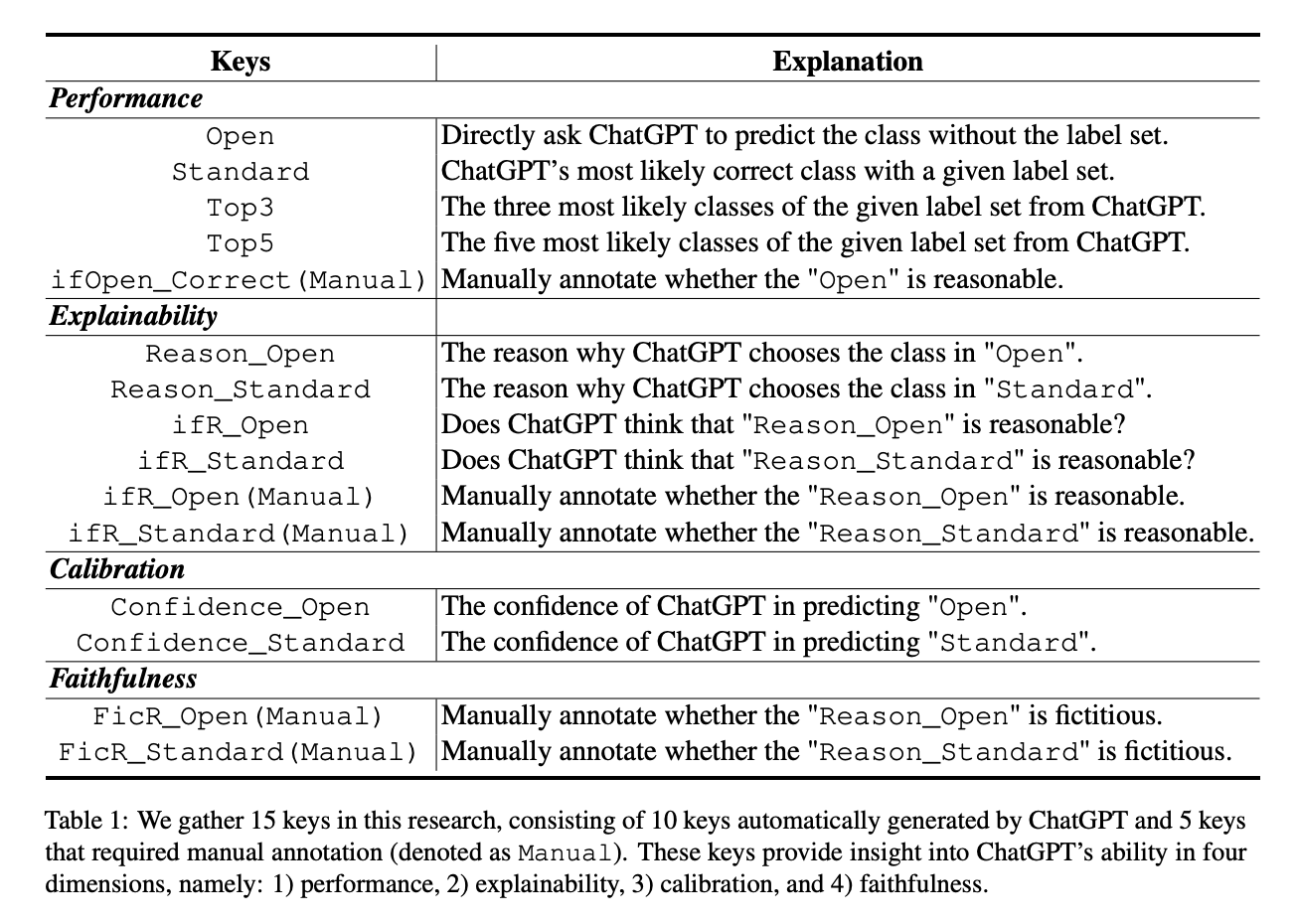
本文主要评估了ChatGPT这种大型语言模型在信息提取方面的能力,作者使用了7个细粒度的信息提取任务来评估ChatGPT的性能、可解释性、校准度和可信度。作者发现,在标准信息提取设置下,ChatGPT的性能较差,但在开放式信息提取设置下表现出色,且其决策的解释具有高质量和可信度。不过,ChatGPT存在过度自信的问题,导致其校准度较低。
此外,ChatGPT在大多数情况下对原始文本的忠实度很高。最后,作者手动注释并发布了7个细粒度信息提取任务的测试集,包含14个数据集,以进一步促进研究。

欢迎进入交流群
相关文章
