LG – 机器学习 CV – 计算机视觉 CL – 计算与语言 AS – 音频与语音 RO – 机器人
转自爱可可爱生活
摘要:以前所未有的规模实现Transformer模型的高效推断、基于扩散模型的语义图像合成、面向导航的视觉预训练、Epinet对分布漂移的鲁棒性、对记忆训练样本遗忘情况的度量、从全局角度重新思考基于可微模拟的优化、视频自监督学习综述、基于问答蓝图的条件式生成、从法律和256GB开源法律数据集学习负责任的数据过滤
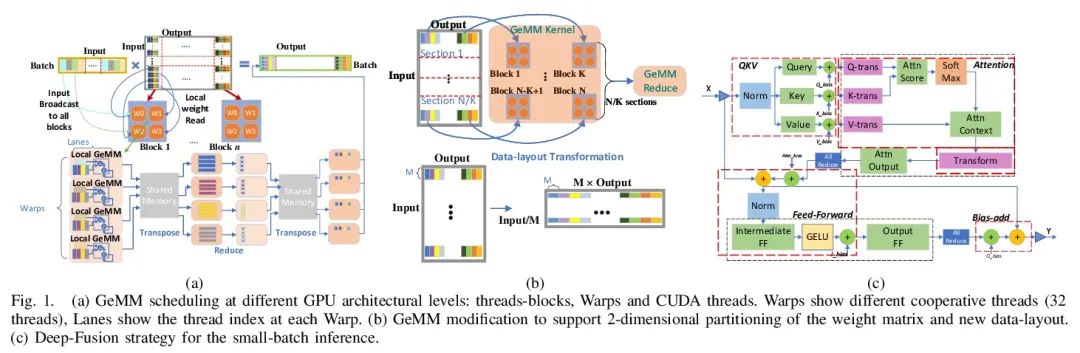
1、[LG] DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
R Y Aminabadi, S Rajbhandari, M Zhang, A A Awan, C Li, D Li, E Zheng, J Rasley, S Smith…
[Microsoft Corporation] (2022)
DeepSpeed Inference:以前所未有的规模实现Transformer模型的高效推断。过去几年见证了基于Transformer的模型的成功,其规模和应用场景持续积极增长。目前,Transformer模型的情况越来越多样化:模型的规模变化很大,最大的有千亿级参数;由于专家混合模型引入的稀疏性,模型的特征也不同;目标应用场景可以是延迟关键型或吞吐量导向型;部署硬件可以是单GPU系统或多GPU系统,具有不同类型的内存和存储,等等。在这种日益增长的多样性和Transformer模型快速发展的背景下,设计一个高性能和高效的推理系统是极具挑战性的。本文提出DeepSpeed Inference,一种用于Transformer模型推理的综合系统解决方案,以解决上述挑战。DeepSpeed Inference包括:(1)一个多GPU推理解决方案,当密集和稀疏Transformer模型适合聚合GPU内存时,可以最大限度减少延迟,同时最大限度提高吞吐量;(2)一个异构推理解决方案,除了GPU内存和计算外,还利用CPU和NVMe内存,使不适合聚合GPU内存的大型模型实现高产出推理。DeepSpeed Inference在面向延迟的情况下比最先进的技术减少了7.3倍的延迟,在面向吞吐量的情况下增加了1.5倍以上的吞吐量。此外,通过利用数百个GPU,在实时延迟限制下实现了万亿级参数规模的推理,这是推理的一个前所未有的规模。可以推理出比纯GPU解决方案大25倍的模型,同时提供84 TFLOPS的高吞吐量(超过A6000峰值的50%)。
The past several years have witnessed the success of transformer-based models, and their scale and application scenarios continue to grow aggressively. The current landscape of transformer models is increasingly diverse: the model size varies drastically with the largest being of hundred-billion parameters; the model characteristics differ due to the sparsity introduced by the Mixture-of-Experts; the target application scenarios can be latency-critical or throughput-oriented; the deployment hardware could be singleor multi-GPU systems with different types of memory and storage, etc. With such increasing diversity and the fast-evolving pace of transformer models, designing a highly performant and efficient inference system is extremely challenging. In this paper, we present DeepSpeed Inference, a comprehensive system solution for transformer model inference to address the above-mentioned challenges. DeepSpeed Inference consists of (1) a multi-GPU inference solution to minimize latency while maximizing the throughput of both dense and sparse transformer models when they fit in aggregate GPU memory, and (2) a heterogeneous inference solution that leverages CPU and NVMe memory in addition to the GPU memory and compute to enable high inference throughput with large models which do not fit in aggregate GPU memory. DeepSpeed Inference reduces latency by up to 7.3× over the state-of-the-art for latency oriented scenarios and increases throughput by over 1.5x for throughput oriented scenarios. Moreover, it enables trillion parameter scale inference under real-time latency constraints by leveraging hundreds of GPUs, an unprecedented scale for inference. It can inference 25× larger models than with GPU-only solutions, while delivering a high throughput of 84 TFLOPS (over 50% of A6000 peak).
https://arxiv.org/abs/2207.00032


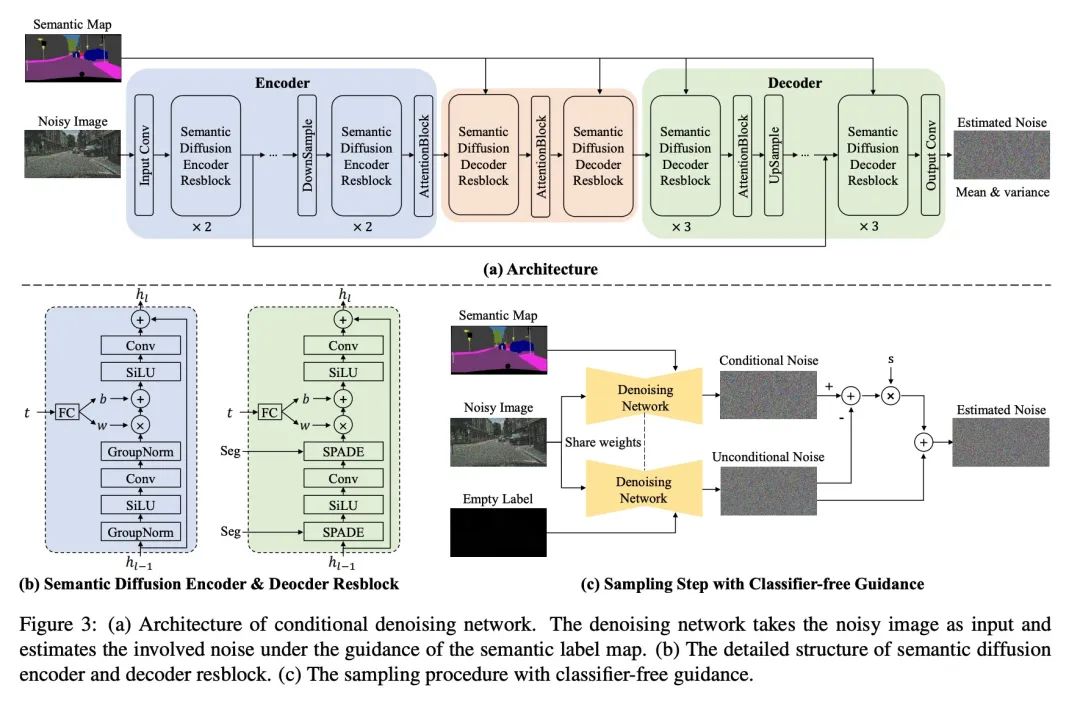
2、[CV] Semantic Image Synthesis via Diffusion Models
W Wang, J Bao, W Zhou, D Chen, D Chen, L Yuan, H Li
[University of Science and Technology of China (USTC) & Microsoft Research Asia & Microsoft Cloud+AI]
基于扩散模型的语义图像合成。与生成对抗网络(GAN)相比,去噪扩散概率模型(DDPM)在各种图像生成任务中取得了显著的成功。最近关于语义图像合成的工作主要遵循事实上基于GAN的方法,可能导致生成的图像的质量或多样性不令人满意。本文提出一种基于DDPM的语义图像合成新框架。与之前的条件扩散模型直接将语义布局和噪声图像作为U-Net结构的输入不同,它可能没有充分利用输入语义掩码中的信息,所提出框架对语义布局和噪声图像进行不同的处理,将噪声图像输入到U-Net结构的编码器中,而语义布局则通过多层空间适应性归一化运算器输入到解码器中。为进一步提高语义图像合成的生成质量和语义可解释性,引入了无分类器指导采样策略,该策略承认采样过程中无条件模型的得分。在三个基准数据集上进行的广泛实验证明了所提出方法的有效性,在保真度(FID)和多样性(LPIPS)方面取得了最先进的性能。
Denoising Diffusion Probabilistic Models (DDPMs) have achieved remarkable success in various image generation tasks compared with Generative Adversarial Nets (GANs). Recent work on semantic image synthesis mainly follows the de facto GAN-based approaches, which may lead to unsatisfactory quality or diversity of generated images. In this paper, we propose a novel framework based on DDPM for semantic image synthesis. Unlike previous conditional diffusion model directly feeds the semantic layout and noisy image as input to a U-Net structure, which may not fully leverage the information in the input semantic mask, our framework processes semantic layout and noisy image differently. It feeds noisy image to the encoder of the U-Net structure while the semantic layout to the decoder by multi-layer spatially-adaptive normalization operators. To further improve the generation quality and semantic interpretability in semantic image synthesis, we introduce the classifier-free guidance sampling strategy, which acknowledge the scores of an unconditional model for sampling process. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our proposed method, achieving state-of-the-art performance in terms of fidelity (FID) and diversity (LPIPS). *Corresponding author: Jianmin Bao.
https://arxiv.org/abs/2207.00050




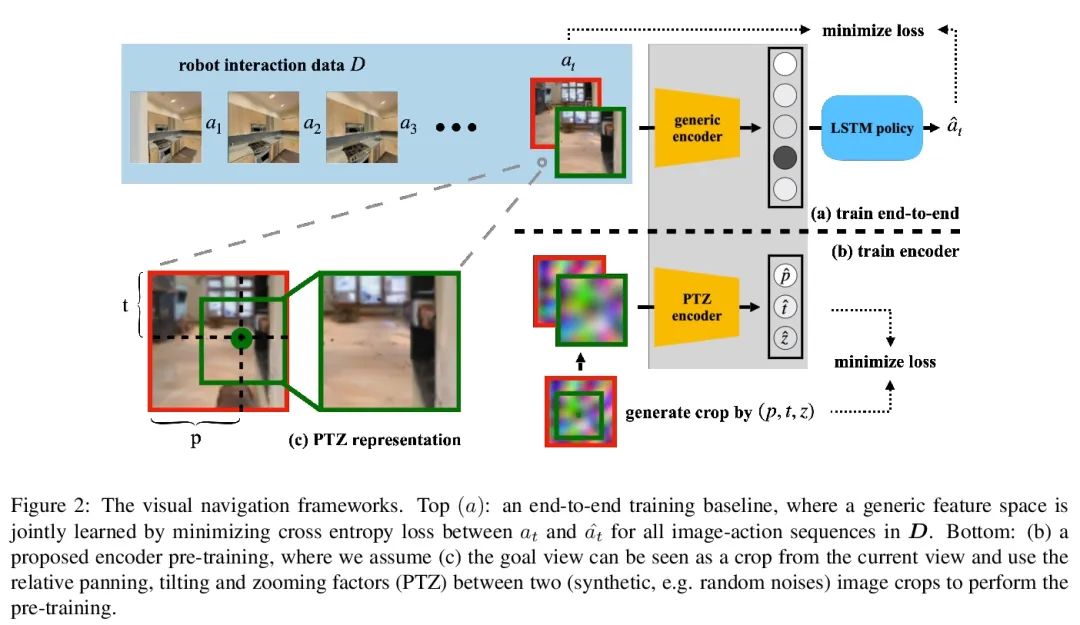
3、[CV] Visual Pre-training for Navigation: What Can We Learn from Noise?
Y Wang, C Ko
[MIT CSAIL & MIT RLE]
面向导航的视觉预训练:我们能从噪声中了解到什么?感知运动控制的一个强大范式是直接从观察中预测行动。训练这样一个端到端的系统,可以使对下游任务有用的表示自动出现。在视觉导航中,智能体可以通过关联其视图的变化与所采取的行动来学习导航,而无需任何人工设计。然而,由于缺乏归纳偏差,系统的数据效率很低,在搜索和救援等场景中不实用,因为与环境互动收集数据的成本很高。本文假设,通过预测与目标相对应的当前视图的位置和大小,可以为导航策略学习到当前视图和目标视图的充分表示。本文进一步表明,以自监督方式对这种随机裁剪预测进行训练,纯粹的随机噪声图像可以很好地迁移到自然室内图像。学到的表示可以被引导,在很少交互数据下有效地学习到一个导航策略。
A powerful paradigm for sensorimotor control is to predict actions from observations directly. Training such an end-to-end system allows representations that are useful for the downstream tasks to emerge automatically. In visual navigation, an agent can learn to navigate without any manual designs by correlating how its views change with the actions being taken. However, the lack of inductive bias makes this system data-inefficient and impractical in scenarios like search and rescue, where interacting with the environment to collect data is costly. We hypothesize a sufficient representation of the current view and the goal view for a navigation policy can be learned by predicting the location and size of a crop of the current view that corresponds to the goal. We further show that training such random crop prediction in a self-supervised fashion purely on random noise images transfers well to natural home images. The learned representation can then be bootstrapped to learn a navigation policy efficiently with little interaction data. Code is available at https://github.com/ yanweiw/noise2ptz.
https://arxiv.org/abs/2207.00052




4、[LG] Robustness of Epinets against Distributional Shifts
X Lu, I Osband, S M Asghari, S Gowal, V Dwaracherla, Z Wen, B V Roy
[DeepMind]
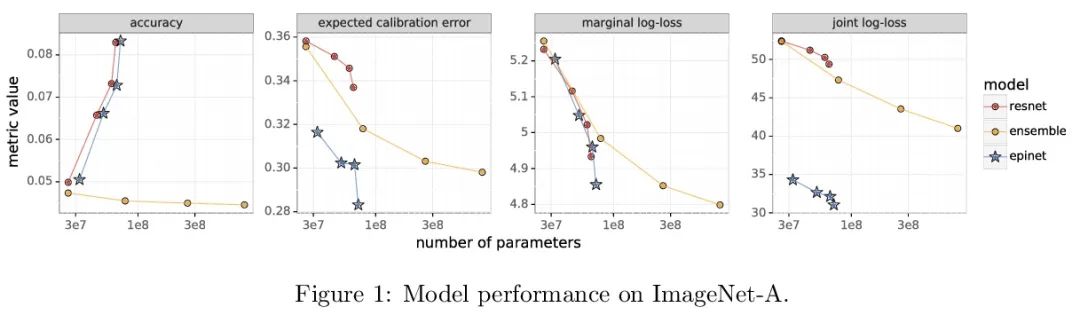
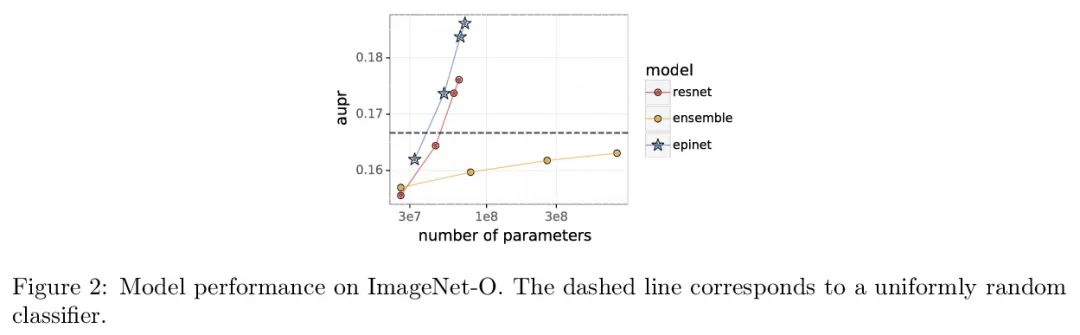
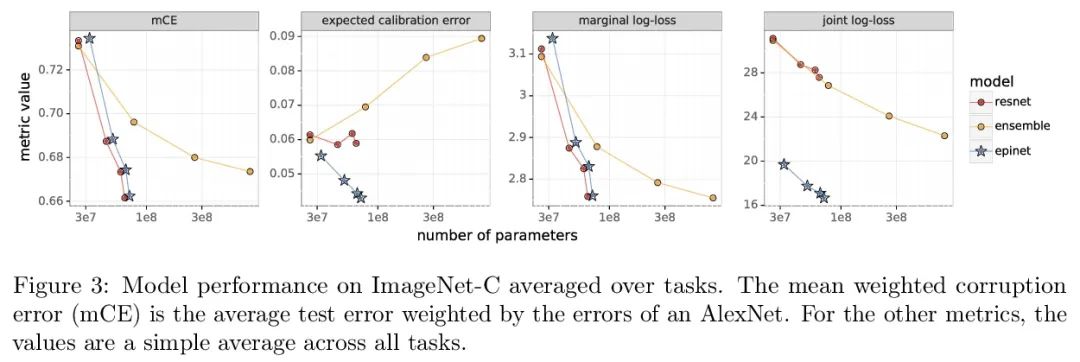
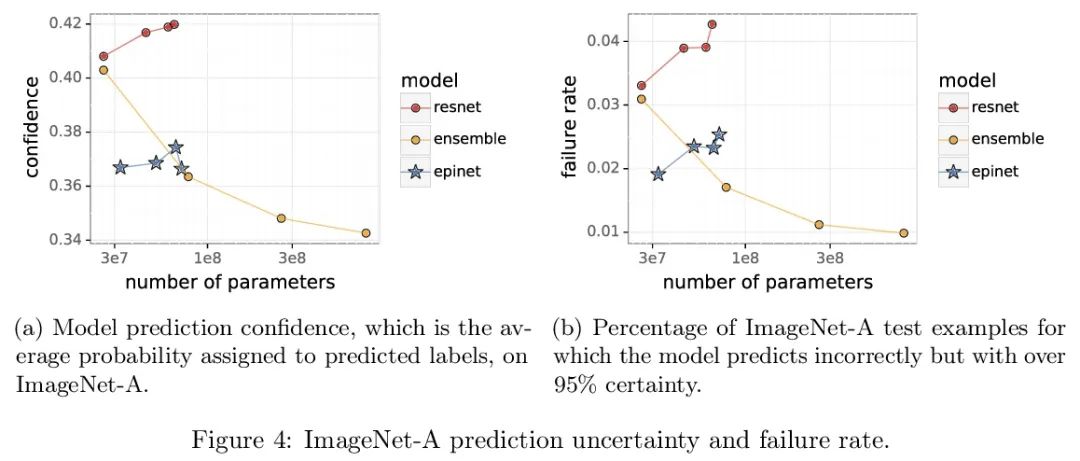
Epinet对分布漂移的鲁棒性。最近的工作介绍了Epinet作为深度学习中不确定性建模的一种新方法。Epinets是一种添加到传统神经网络中的小型神经网络,合在一起可以产生预测分布。特别是,用Epinets可以大大提高跨多个输入的联合预测的质量,可以衡量一个神经网络对其不了解对象的了解程度。本文研究了Epinet是否能在分布漂移下提供类似的优势。实验发现,在整个ImageNet-A/O/C中,Epinet普遍提高了鲁棒性指标。此外,这些改进甚至比那些计算成本低几个数量级的大型集成体所提供的改进更为显著。然而,与分布鲁棒深度学习中的突出问题相比,这些改进相对较小。Epinet可能是工具箱中的一个有用工具,但远不是完整的解决方案。
Recent work introduced the epinet as a new approach to uncertainty modeling in deep learning (Osband et al., 2022a). An epinet is a small neural network added to traditional neural networks, which, together, can produce predictive distributions. In particular, using an epinet can greatly improve the quality of joint predictions across multiple inputs, a measure of how well a neural network knows what it does not know (Osband et al., 2022a). In this paper, we examine whether epinets can offer similar advantages under distributional shifts. We find that, across ImageNet-A/O/C, epinets generally improve robustness metrics. Moreover, these improvements are more significant than those afforded by even very large ensembles at orders of magnitude lower computational costs. However, these improvements are relatively small compared to the outstanding issues in distributionally-robust deep learning. Epinets may be a useful tool in the toolbox, but they are far from the complete solution.
https://arxiv.org/abs/2207.00137

5、[LG] Measuring Forgetting of Memorized Training Examples
M Jagielski, O Thakkar, F Tramèr, D Ippolito, K Lee, N Carlini, E Wallace, S Song, A Thakurta, N Papernot, C Zhang
[Google & UC Berkeley]
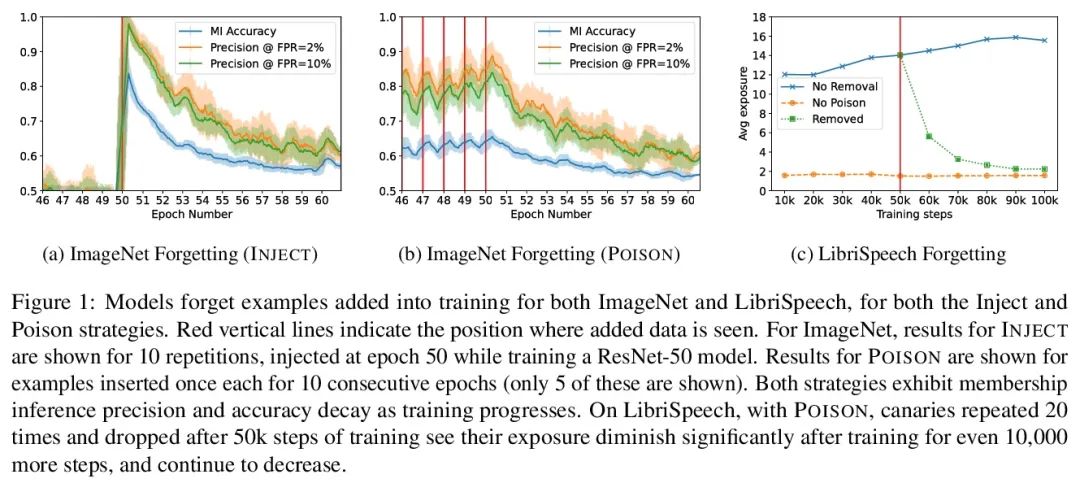
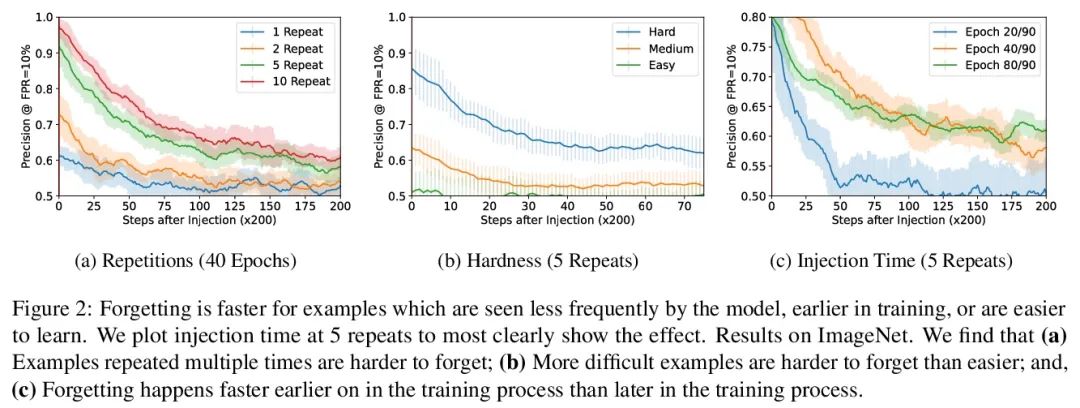
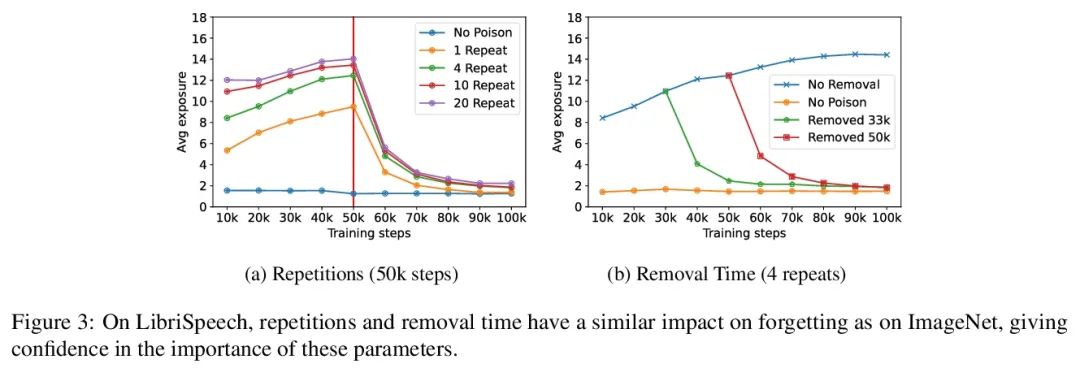
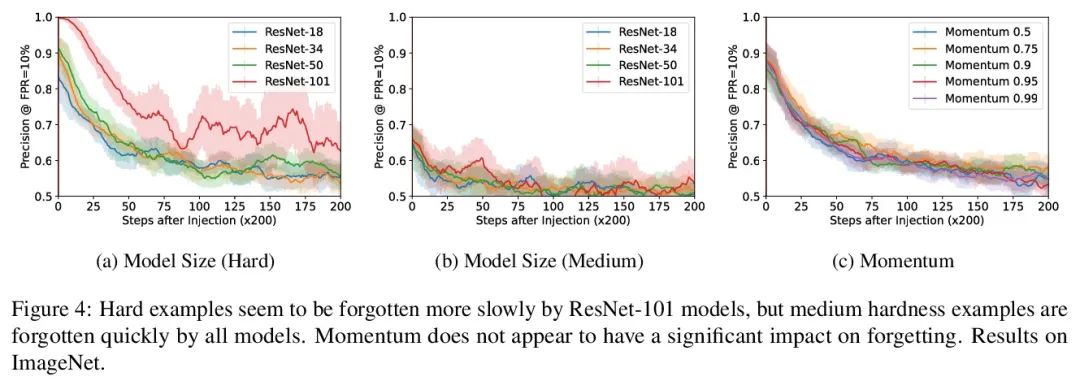
对记忆训练样本遗忘情况的度量。机器学习模型表现出两种看似矛盾的现象:训练数据的记忆和各种形式的遗忘。在记忆中,模型会过拟合特定的训练样本,容易受到隐私攻击的影响。在遗忘中,训练早期出现的样本在训练结束时被遗忘。本文将这些现象联系起来,提出一种技术来衡量模型在多大程度上”遗忘”了训练样本的具体内容,使其在最近没有看到的样本上变得不容易受到隐私攻击。本文表明,虽然非凸性可以防止在最坏情况下发生遗忘,但根据经验,标准图像和语音模型确实会随着时间的推移而遗忘样本。将非确定性看作一种潜在的解释,表明确定性训练的模型不会遗忘。实验结果表明,在用极其庞大的数据集进行训练时,早期看到的样本——例如那些用于预训练模型的样本——可能会以牺牲后来看到的样本为代价来获得隐私的好处。
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models “forget” the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets—for instance those examples used to pre-train a model—may observe privacy benefits at the expense of examples seen later.
https://arxiv.org/abs/2207.00099

另外几篇值得关注的论文:
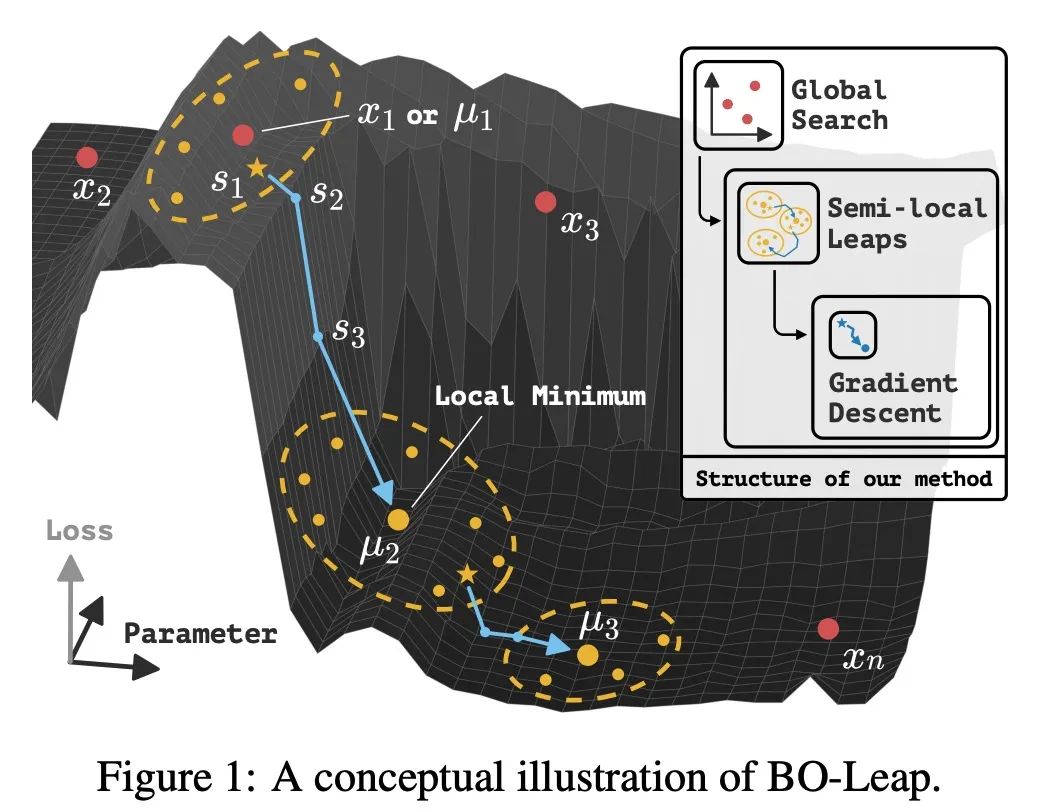
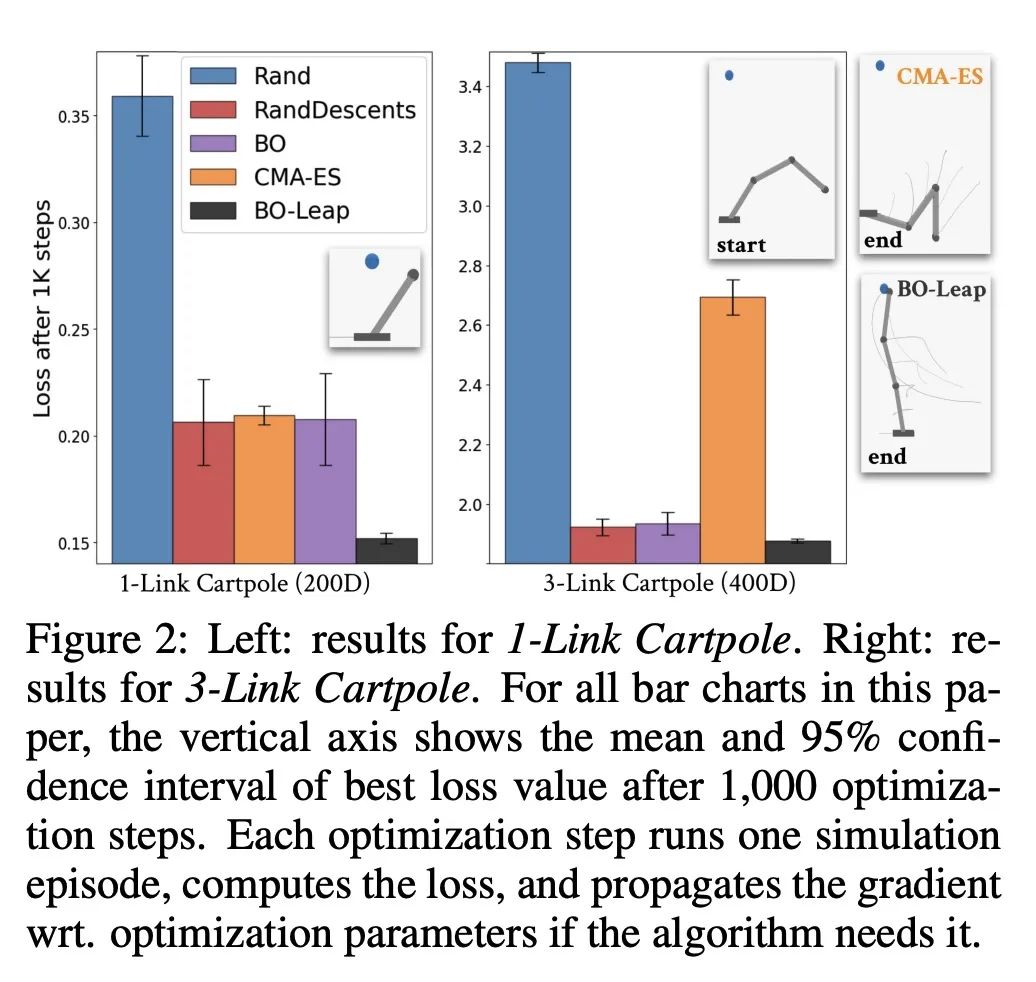
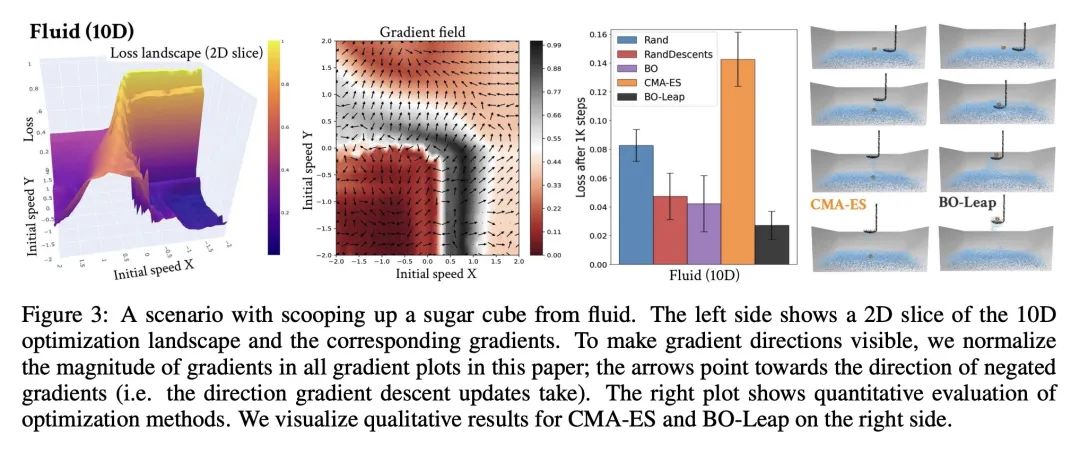
[LG] Rethinking Optimization with Differentiable Simulation from a Global Perspective
从全局角度重新思考基于可微模拟的优化
R Antonova, J Yang, K M Jatavallabhula, J Bohg
[Stanford University & MIT]
https://arxiv.org/abs/2207.00167

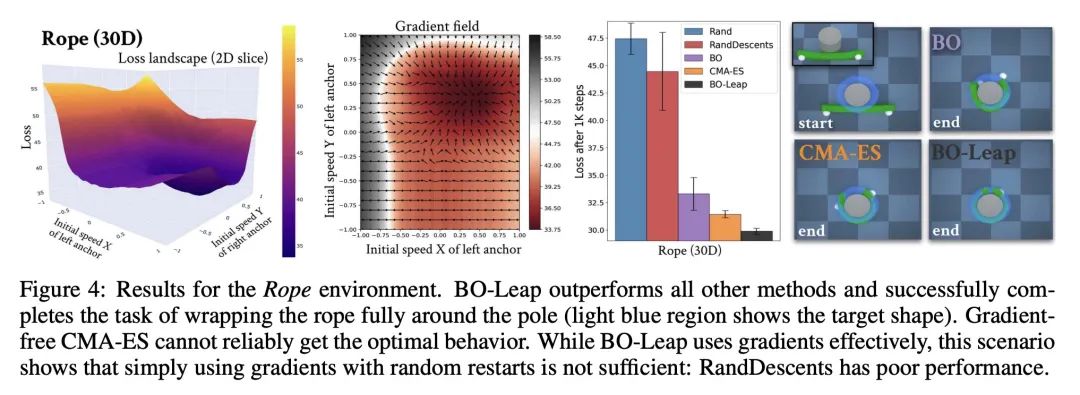
[CV] Self-Supervised Learning for Videos: A Survey
视频自监督学习综述
M C. Schiappa, Y S. Rawat, M Shah
[University of Central Florida]
https://arxiv.org/abs/2207.00419

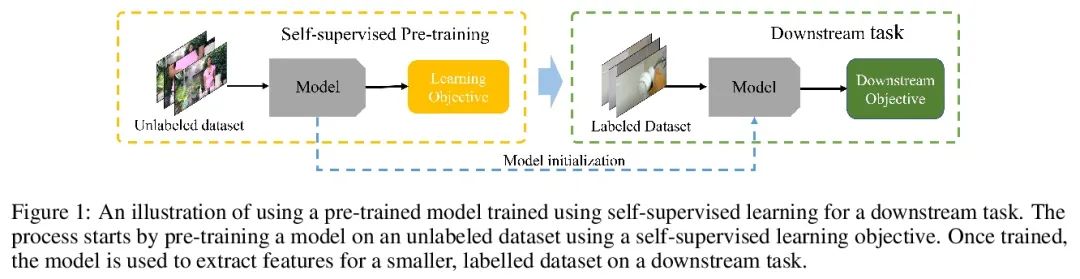
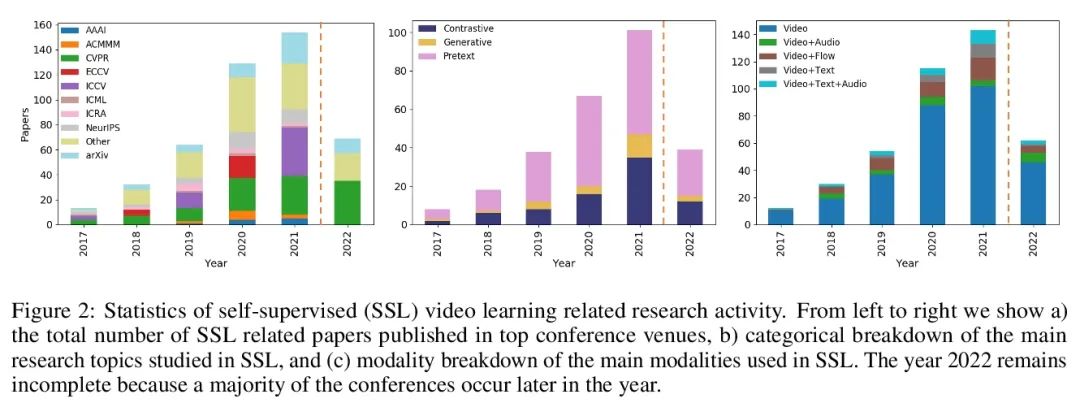
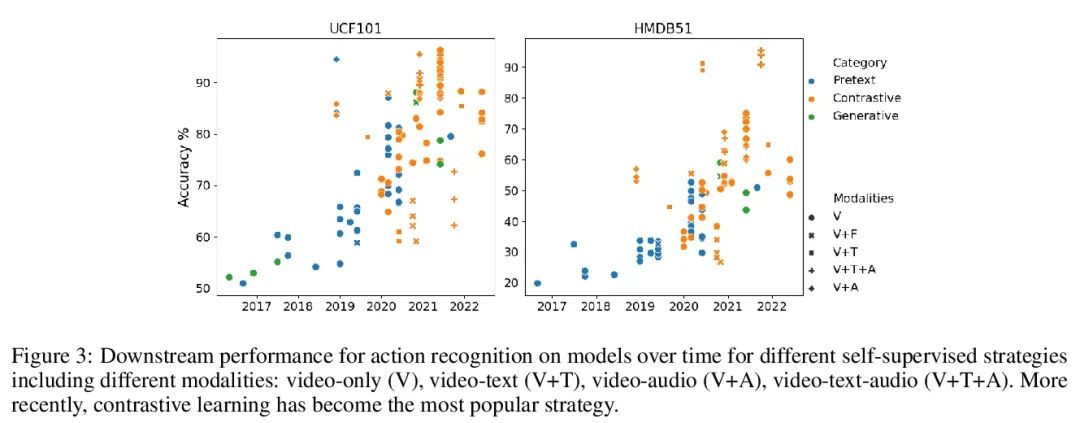
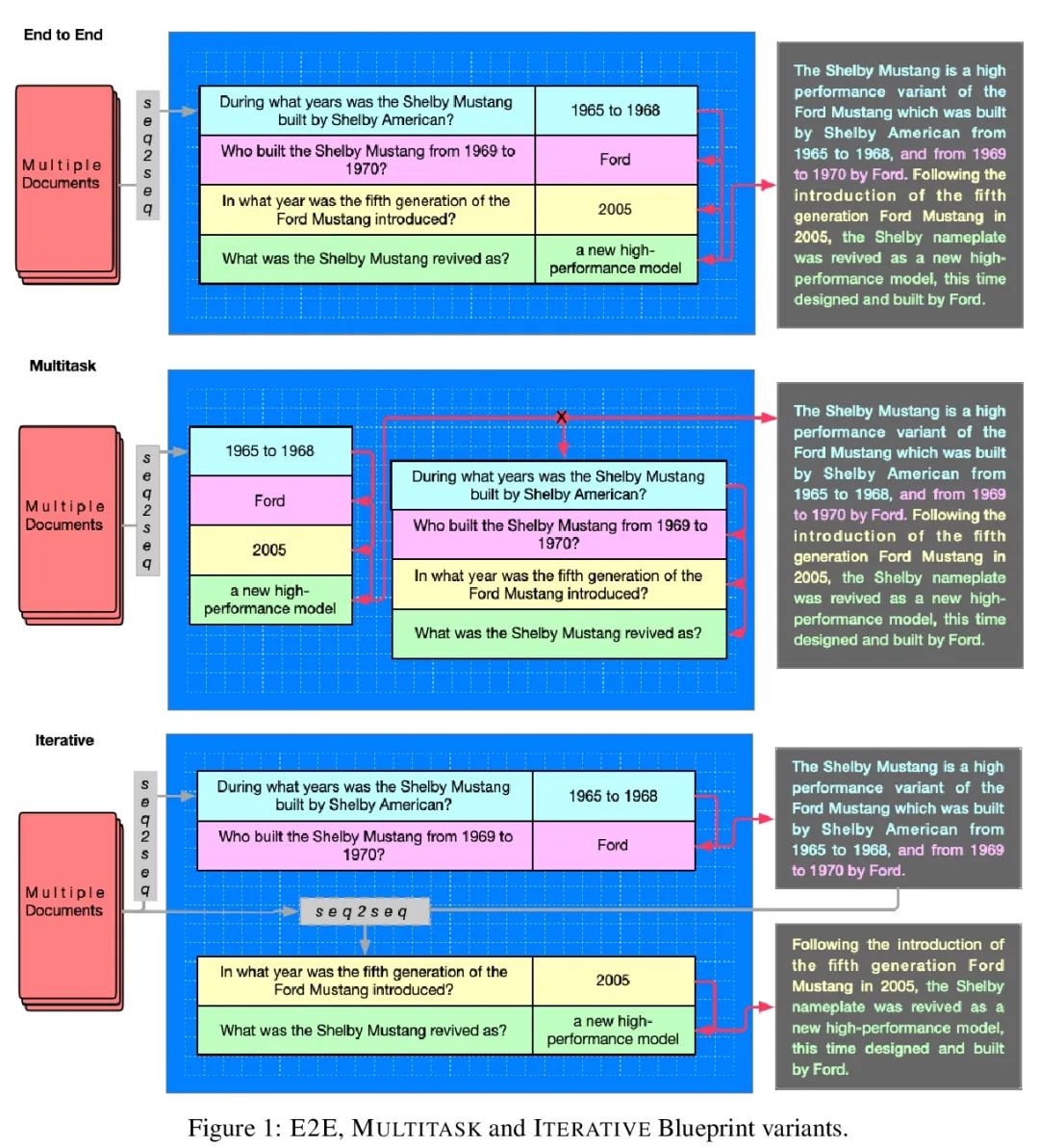
[CL] Conditional Generation with a Question-Answering Blueprint
基于问答蓝图的条件式生成
S Narayan, J Maynez, R K Amplayo, K Ganchev, A Louis, F Huot, D Das, M Lapata
[Google Research]
https://arxiv.org/abs/2207.00397

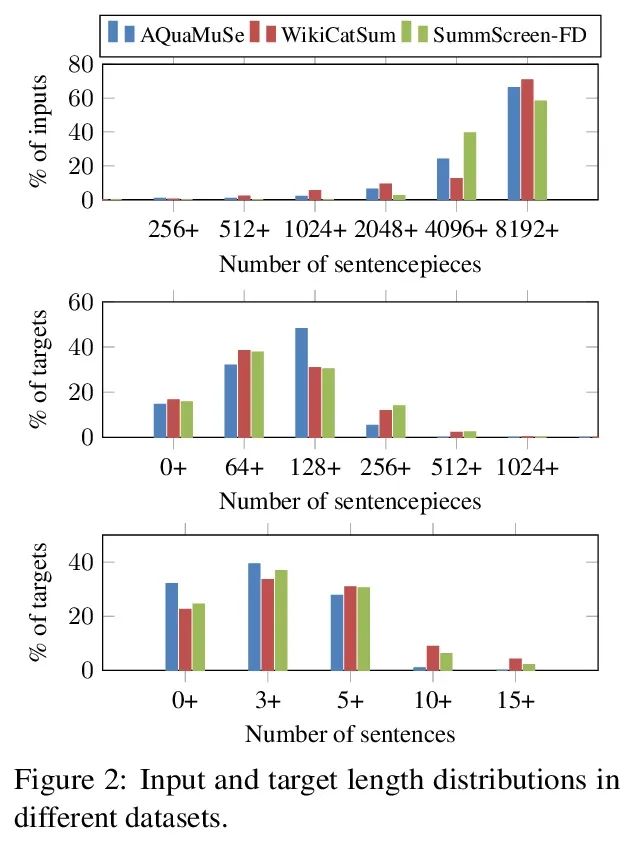
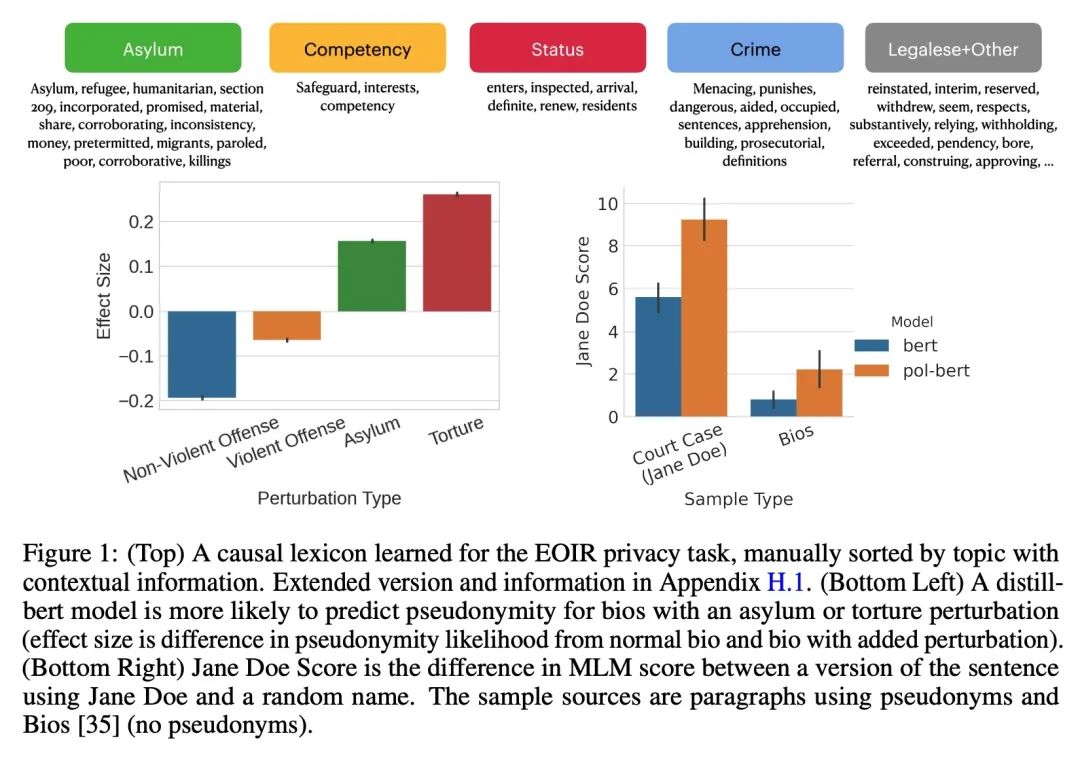
[CL] Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset
Pile of Law:从法律和256GB开源法律数据集学习负责任的数据过滤
P Henderson, M S. Krass, L Zheng, N Guha, C D. Manning, D Jurafsky, D E. Ho
[Stanford University]
https://arxiv.org/abs/2207.00220

相关文章
