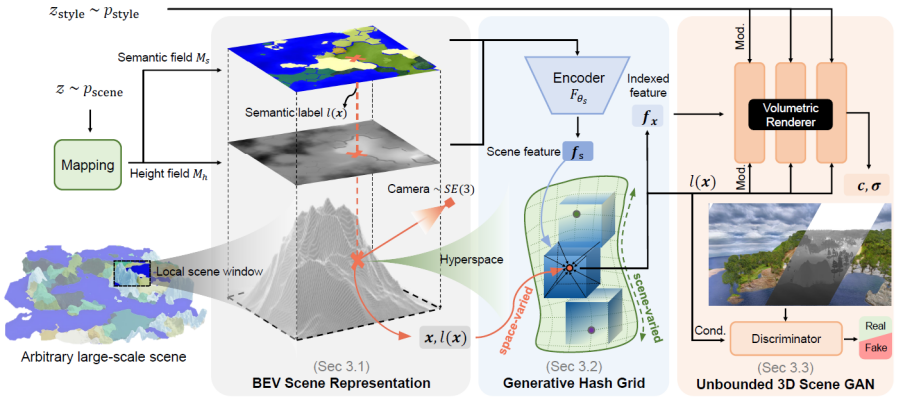
来自南洋理工大学 S-Lab 的研究者提出了一个新的框架 SceneDreamer,专注于从海量无标注自然图片中学习无界三维场景的生成模型。

-
项目主页:https://scene-dreamer.github.io/ -
代码:https://github.com/FrozenBurning/SceneDreamer -
论文:https://arxiv.org/abs/2302.01330 -
在线 Demo:https://huggingface.co/spaces/FrozenBurning/SceneDreamer
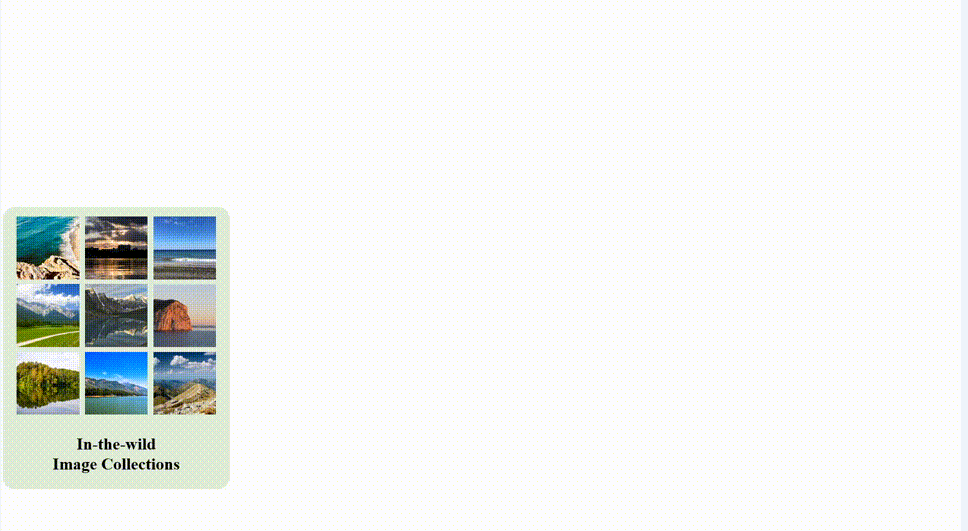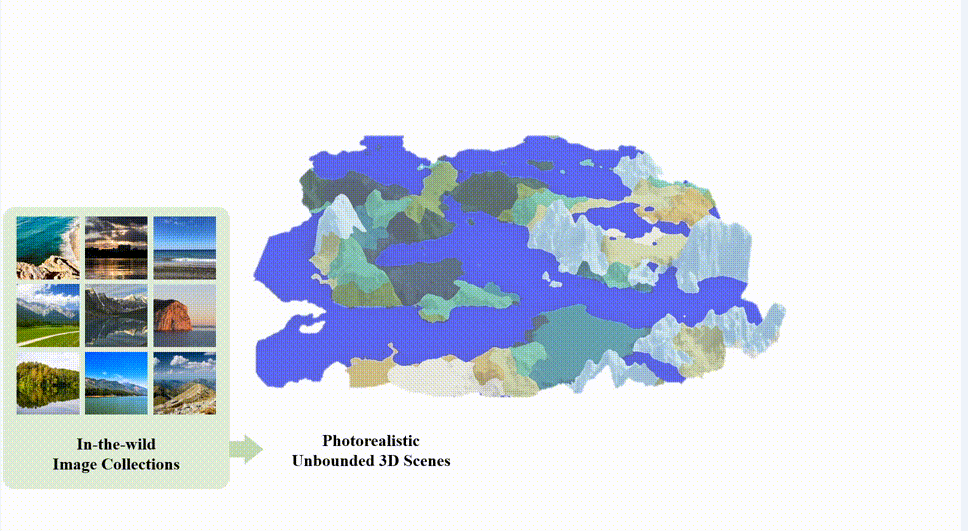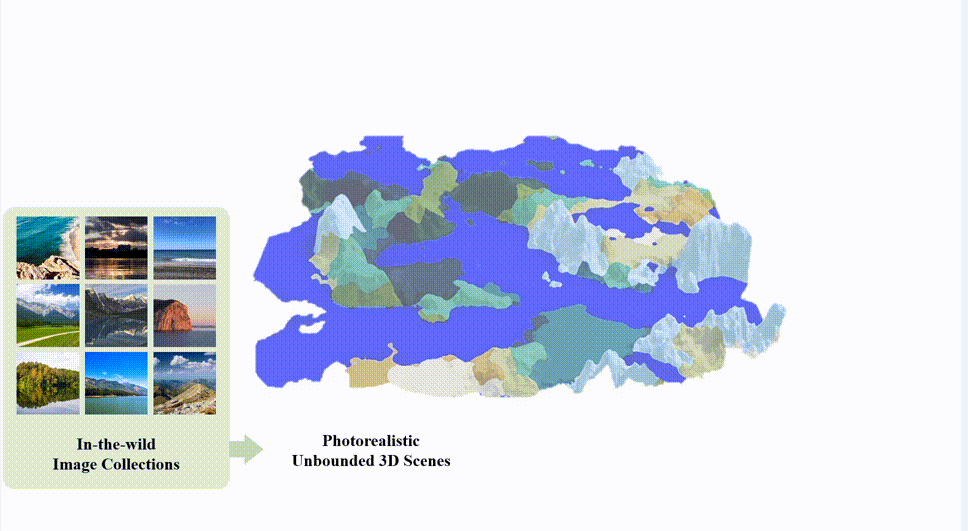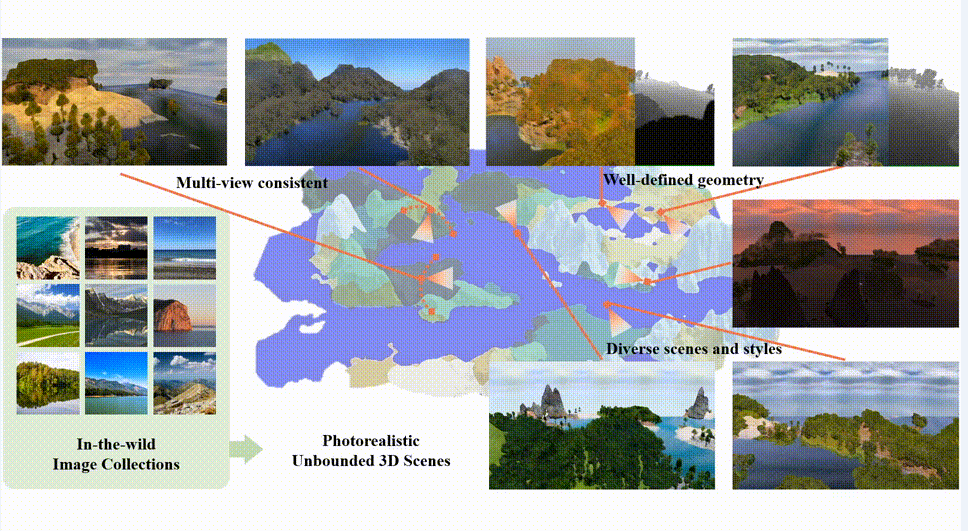
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
