Track Anything: Segment Anything Meets Videos
https://arxiv.org/abs/2304.11968
https://github.com/gaomingqi/Track-Anything
本文提出一种名为“Track Anything Model”的视频交互追踪和分割模型,在视频中可以快速高效地跟踪任意目标,并获得令人满意的分割结果,只需要少量的人工干预,具有较高的实用性和适用性。
解决问题: 这篇论文旨在解决Segment Anything Model (SAM)在视频中表现不佳的问题,提出了一种名为Track Anything Model (TAM)的模型,实现了高性能的交互式跟踪和分割。

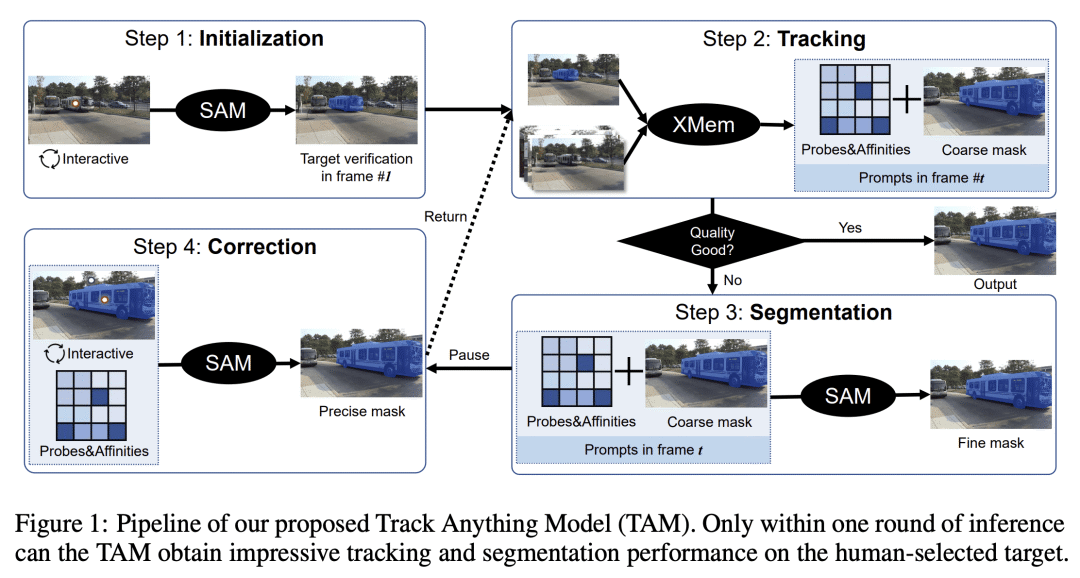
关键思路: TAM模型通过少量的人类参与,即几次点击,就能追踪视频中任何感兴趣的对象,并在一次推理中获得令人满意的结果,而无需额外的训练。相比于当前领域的研究,该论文的关键思路是通过交互式设计实现视频对象跟踪和分割。
其他亮点: 该论文的实验设计使用了开源数据集,并且开源了代码资源。该模型的交互设计在视频对象跟踪和分割方面表现优异,值得进一步深入研究。
关于作者:
Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, Feng Zheng
南方科技大学SUSTech VIP Lab
论文摘要:这篇摘要介绍了一种名为Track Anything Model(TAM)的模型,它可以在视频中实现高性能的交互式跟踪和分割。相比于Segment Anything Model(SAM)在图像分割方面的强大能力和与不同提示的高交互性,我们发现它在视频中的一致分割表现很差。
因此,本报告提出了TAM,只需进行少量的人类参与,即几次点击,就可以跟踪视频中感兴趣的任何内容,并在一次推理中得到令人满意的结果。这种交互式设计在视频对象跟踪和分割方面表现出色,而且无需额外的训练。所有资源都可以在\url{https://github.com/gaomingqi/Track-Anything}上获得。希望这项工作能促进相关研究的发展。
-
动机:基于Segment Anything Model(SAM)在图像分割中卓越的性能和与不同提示的高交互性,发现SAM在视频的一致分割方面表现不佳,因此需要提出一种新的模型来解决这一问题。 -
方法:将SAM应用于视频跟踪和分割中,提出一种基于时间对应构建的交互式追踪和分割模型,只需要少量的人工干预即可实现one-pass推理,有效解决了视频目标感知中的极端困难。 -
优势:在复杂场景中表现出优越的性能和高度的可用性,具有许多潜在的应用。
相关文章
