Any-to-Any Generation via Composable Diffusion
Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, Mohit Bansal
[Microsoft & University of North Carolina at Chapel Hill]
基于可组合扩散的Any-to-An的生成
CoDi是一种创新的多模态生成模型,能自由生成任意组合的输出模态,并在生成质量方面超越或与单模态合成的最先进方法持平。
-
动机:开发一种能生成任意组合输出形式(如语言、图像、视频或音频)的生成模型。与现有的生成式AI系统不同,CoDi能并行生成多种模态,且其输入不限于文本或图像等子集模态。提出在输入和输出空间中对模态进行对齐的方法,使得CoDi能自由地对任意输入组合进行条件生成,并生成任意一组模态,即使这些模态在训练数据中不存在。 -
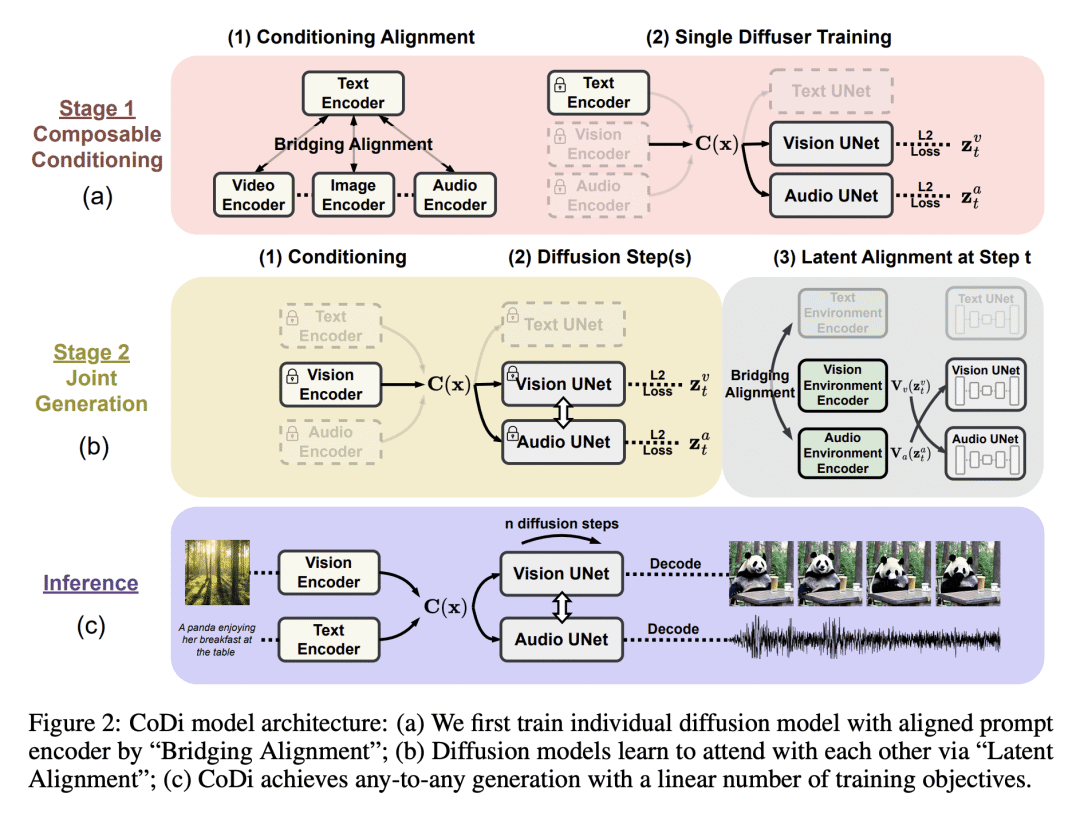
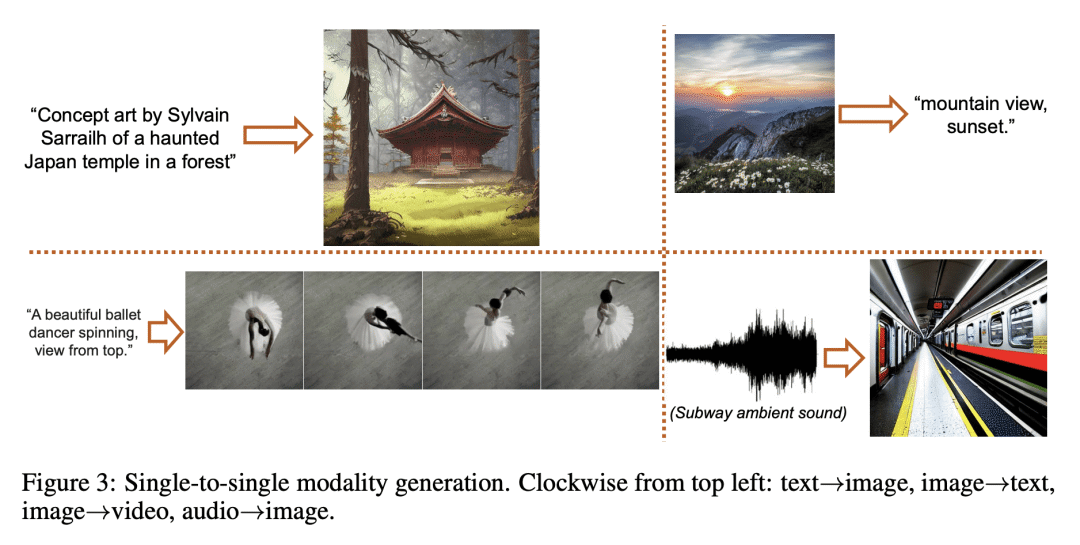
方法:CoDi采用一种新的可组合生成策略,通过在扩散过程中建立共享的多模态空间,实现模态之间的对齐,从而实现模态的同步生成,如时间上对齐的视频和音频。CoDi在生成过程中能高度定制和灵活,实现了强大的联合模态生成质量,并且在单模态合成方面优于或与最先进的单模态合成方法持平。 -
优势:CoDi是一种创新的多模态生成模型,能从各种输入模态中同时处理和生成多种模态(包括文本、图像、视频和音频)。通过对齐模态空间,能自由地生成各种组合的输出模态,具有高质量和连贯性。在推动更具吸引力和全面的人机交互方面迈出了重要的一步,为未来生成人工智能的研究奠定了坚实的基础。
https://arxiv.org/abs/2305.11846 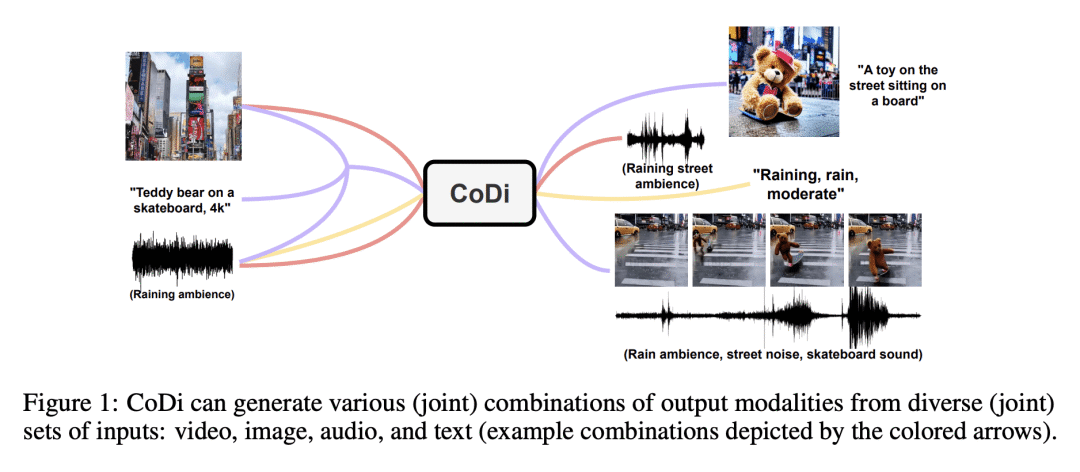
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
