Mahan Fathi, Jonathan Pilault, Pierre-Luc Bacon, Christopher Pal, Orhan Firat, Ross Goroshin
[Google DeepMind & Mila]
Block-State Transformer
要点:
-
动机:解决在处理长序列时,Transformer模型的计算效率和质量问题。尽管Transformer模型在语言建模任务上取得了显著的成果,但其运行时间与输入序列长度呈二次关系,这使得训练这些模型的成本越来越高。此外,Transformer模型在处理长输入分类任务时表现不佳,并且在训练长序列时非常不稳定。
-
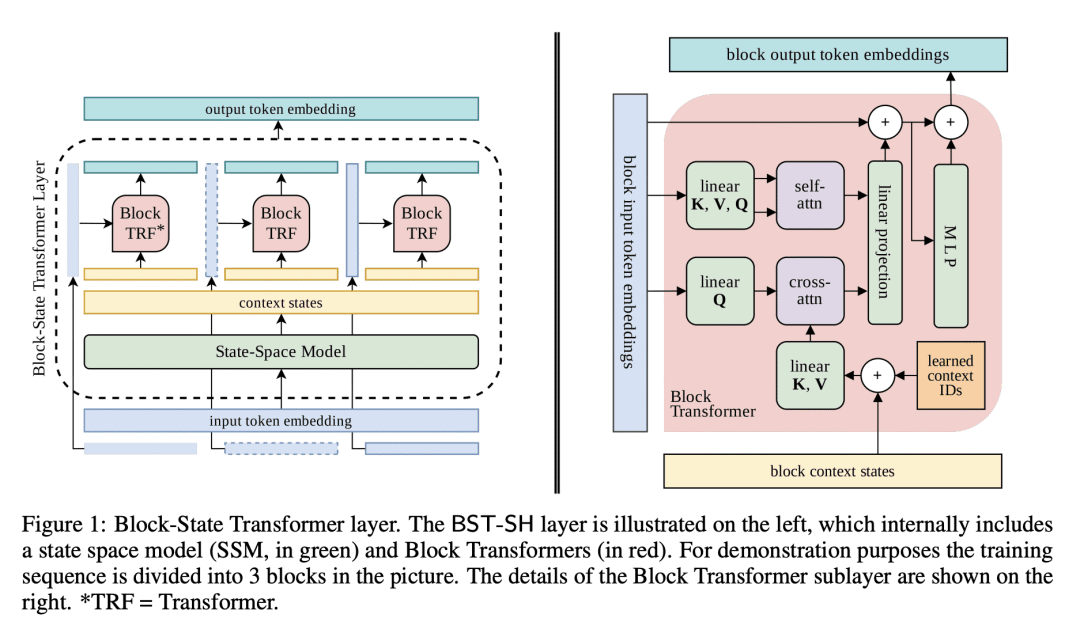
方法:提出一种名为Block-State Transformer(BST)的混合层,该层内部结合了一个用于长期上下文化的状态空间模型(SSM)子层和一个用于短期序列表示的Block Transformer子层。BST模型能处理长输入序列,同时还包含一个注意力机制来预测下一Token。BST是完全并行化的,可以扩展到更长的序列,并且与可比的基于Transformer的层相比,速度提高了10倍。
-
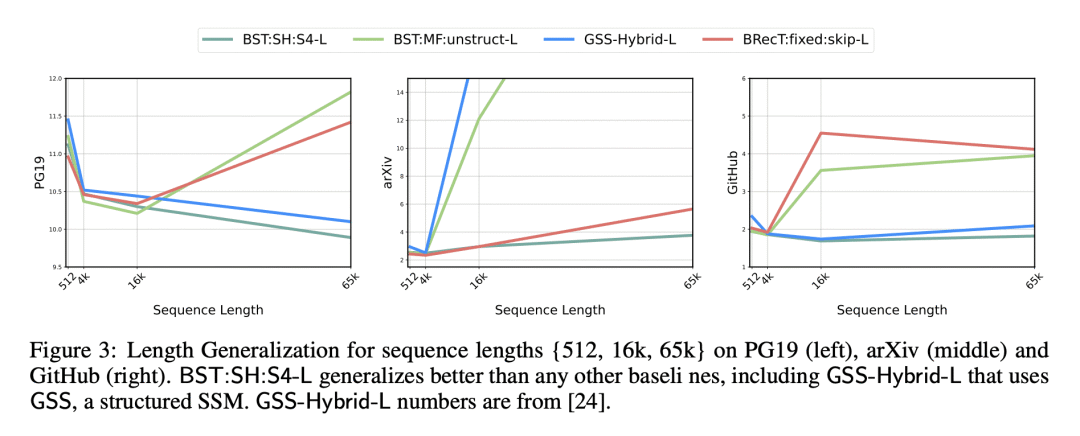
优势:BST模型具有更高的计算效率和长序列处理能力。通过引入SSM进行上下文化,完全消除了对顺序递归的需求,能完全并行运行混合SSM-Transformer层。此外,BST模型在语言建模困惑度上超越了类似的基于Transformer的架构,并且能够推广到更长的序列。
提出一种新的混合层模型——Block-State Transformer(BST),结合了状态空间模型(SSM)和Block Transformer,能有效处理长序列,提高计算效率,并在语言建模任务上取得了优秀的性能。
https://arxiv.org/abs/2306.09539

相关文章
