?智源社区日报关注订阅?
Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models’ Reasoning Performance
Yao Fu, Litu Ou, Mingyu Chen, Yuhao Wan, Hao Peng, Tushar Khot
来自爱丁堡大学、华盛顿大学、艾伦人工智能研究所、滑铁卢大学
https://github.com/FranxYao/chain-of-thought-hub
随着大型语言模型(LLM)的不断发展,它们的评估变得越来越重要,但又具有挑战性。这项工作提出了Chain-of-Thought Hub,这是一个关于大型语言模型多步推理能力的开源评估套件。
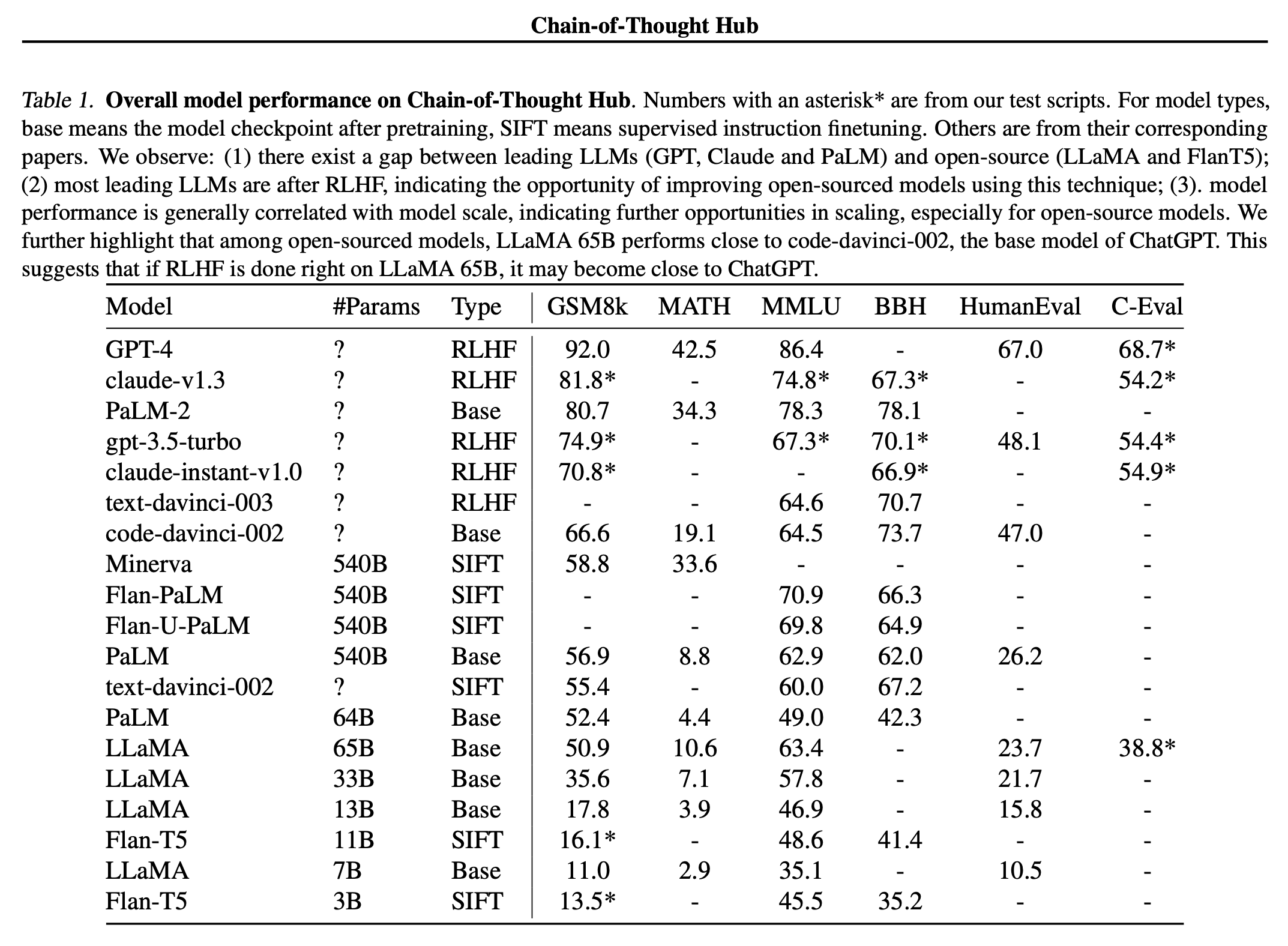
我们之所以对这种设置感兴趣,有两个原因:
(1)从GPT和PaLM模型家族的行为中,我们观察到复杂的推理可能是较弱和更强的LLM之间的关键区别;(2)我们设想大型语言模型将成为下一代计算平台,并培养基于LLM的新应用程序的生态系统,这自然需要基础模型执行复杂的任务,这些任务通常涉及语言和逻辑操作的组成。我们的方法是编制一套具有挑战性的推理基准,以跟踪LLM的进展。
我们目前的结果表明:
(1)模型规模与推理能力明确相关;(2)截至2023年5月,Claude-v1.3和PaLM-2是唯一两个与GPT-4相当的模型,而开源模型仍然落后;(3)LLA-65B的表现与code-davinci-002密切相关,这表明随着从人类反馈(RLHF)中进行强化学习等成功的进一步发展,它有很大的潜力接近GPT-3.5-Turbo。我们的结果还表明,为了赶上开源的努力,社区可能会更专注于构建更好的基础模型和探索RLHF。
相关文章
