本文是SIGKDD 2022入选论文“GPPT: Graph Pre-training and Prompt Tuning to Generalize Graph Neural Networks”的解读。该论文由吉林大学计算机科学与技术学院王英教授课题组完成。本文首次提出“Pre-training、Prompt、Fine-tuning”的概念将下游任务进行重构,使其具有与Pretext相似的任务目标,弥补GNN之间的任务差距,解决由传统GNN预训练中Pretext任务与下游任务之间内在训练目标差距导致的难以引出预训练的图知识、负迁移的问题。实验表明,该训练策略优于其它所有训练策略,包括监督学习、联合训练和传统的迁移学习。

图神经网络(GNNs)已经成为许多现实世界系统中分析图结构数据的技术,包括社交网络、推荐系统和知识图铺谱。GNN的一般方法将输入视为一个底层的计算图,通过跨边缘传递消息学习节点表示。生成的节点表示可用于不同的下游任务,如链路预测、节点分类和节点属性拟合等。
最近在迁移学习领域中通过让GNN捕获可迁移的图模式以推广到不同的下游任务中。具体来说,大多数遵循“预先训练、微调”学习策略:使用容易获取的信息作为Pretext任务(如边缘预测)对GNN进行预训练,以预先训练的模型作为初始化对下游任务进行微调。
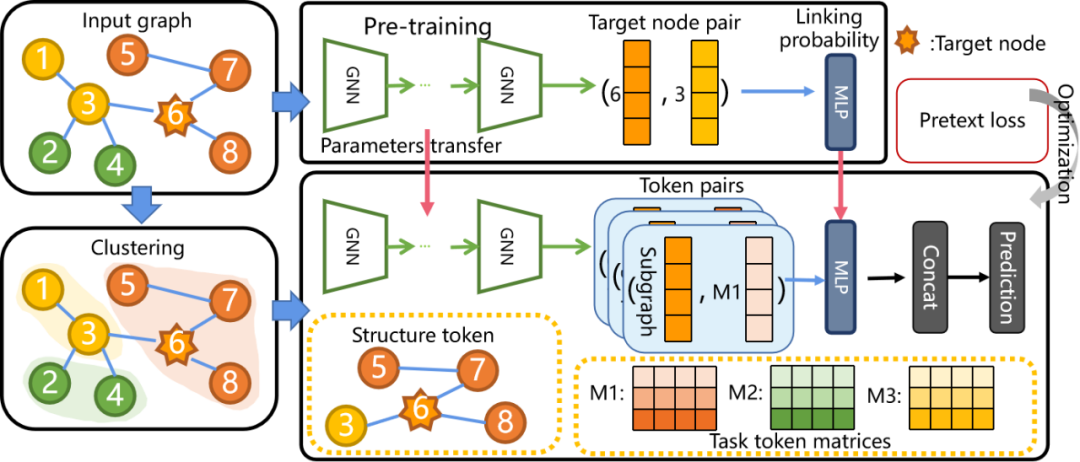
论文注意到传统GNN预训练中Pretext任务与下游任务之间内在训练目标差距,不仅可能无法引出预训练的图知识,甚至会导致负迁移现象。此外,Pretext任务既需要专业知识,也需要繁琐的手工试验。因此,论文首次提出“Pre-training、Prompt、Fine-tuning”的概念将下游任务进行重构,使其成为与Pretext任务相似的目标任务,以弥补预训练目标与微调目标之间的任务差距。为了克服传统“Pre-training、Fine-tuning”的局限性,借鉴了自然语言处理中的“Prompt”技术。由于提示调优是NLP领域中特有的技术,因此很难设计适合GNN的Prompt模板。论文克服了两个主要的挑战:1)如何应用语义提示函数重构图数据中各种图机器学习任务;2)如何设计Prompt模板以更好地重新制定下游应用程序,提出图预训练和提示调优(GPPT)框架。
首先,采用Masked Edge Prediction任务对GNN进行预训练,将下游节点分类任务重构为链接预测任务。然后,为了缩小预训练目标和下游任务目标之间的的差距,利用成对的令牌模板中Graph Prompt函数将独立节点修改为标记对,其中每一个标记对包含代表下游问题的任务令牌(task token)和包含节点信息的结构令牌(structure token)。任务令牌(表示节点标签)和结构令牌(描述节点)可以直接用于微调预训练模型且无需改变分类层。然后,利用节点链接预测得分重新制定节点分类方法,得分最高的任务标记被确定为节点标签。最后,通过实验验证了论文所提出的GPPT在监督学习、联合训练和传统迁移学习中的有效性,以及在小样本设置下这种学习模式的优越性。
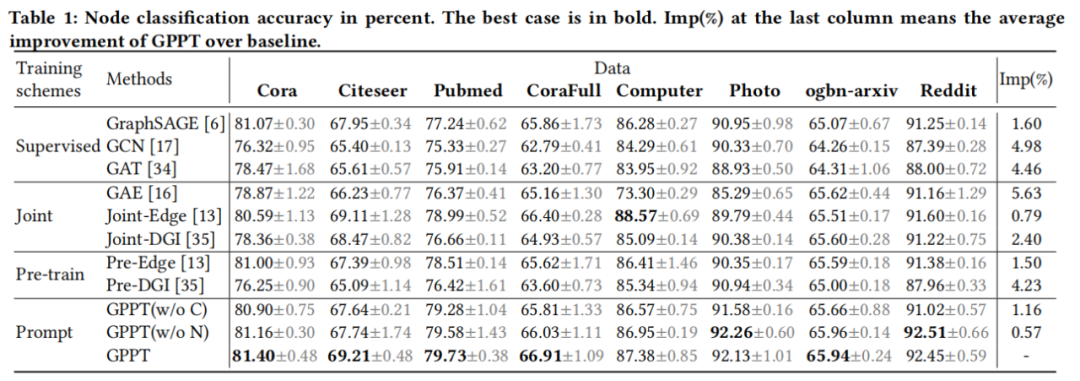
我们在8个流行的基准数据集上评估了提出的框架GPPT,包括引文网络(Cora、Citeseer、Pubmed)、Reddit、CoraFull、Amazon-CoBuy(Computer和Photo)、Ogbn-arxiv。
基于提示的学习方法通常在基准测试上获得最好的性能,其中利用图聚类和邻域结构信息是Prompt令牌设计的关键。
我们创新性地提出了GPPT,首个针对GNN进行“预训练、提示、微调”的迁移学习范式。首次设计了适用于图数据的图提示函数,以重新制定与Pretext任务相似的下游任务,从而减少二者训练目标差距。与此同时,我们还设计了任务和结构令牌生成方法,用于生成节点分类任务中的节点提示。此外,我们提出了平均提示初始化和正交正则化方法来提高提示调优性能。大量的实验表明,GPPT在基准图数据集上优于传统的训练范式,同时提高了调优效率和对下游任务的更好的适应性。在未来的工作中,我们将在更具挑战性的知识图中探索图的提示功能,并尝试通过元学习来改进提示调优。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章