2023 年 7 月,清华大学计算机系 PACMAN 实验室发布稀疏大模型训练系统 SmartMoE,支持用户一键实现 MoE 模型分布式训练,通过自动搜索复杂并行策略,达到开源 MoE 训练系统领先性能。同时,PACMAN 实验室在国际顶级系统会议 USENIX ATC’23 发表长文,作者包括博士生翟明书、何家傲等,通讯作者为翟季冬教授。PACMAN 实验室在机器学习系统领域持续深入研究,SmartMoE 是继 FastMoE, FasterMoE 和 “八卦炉” 后在大模型分布式训练系统上的又一次探索。
欲了解更多相关成果可查看翟季冬教授首页:https://pacman.cs.tsinghua.edu.cn/~zjd

Mixture-of-Experts (MoE) 是一种模型稀疏化技术,因其高效扩展大模型参数量的特性而备受研究者关注。为了提高 MoE 模型的易用性、优化 MoE 模型训练性能,PACMAN 实验室在 MoE 大模型训练系统上进行了系统深入的研究。2021 年初,开源发布了 FastMoE 系统,它是第一个基于 PyTorch 的 MoE 分布式训练系统开源实现,在业界产生了较大的影响力。进一步,为了解决专家并行的稀疏、动态计算模式带来的严重性能问题,FasterMoE 系统地分析、优化了专家并行策略。FasterMoE 中设计的「影子专家」技术显著缓解了负载不均问题、通信 – 计算协同调度算法有效隐藏了 all-to-all 通信的高延迟。FasterMoE 成果发表在 PPoPP’22 国际会议。
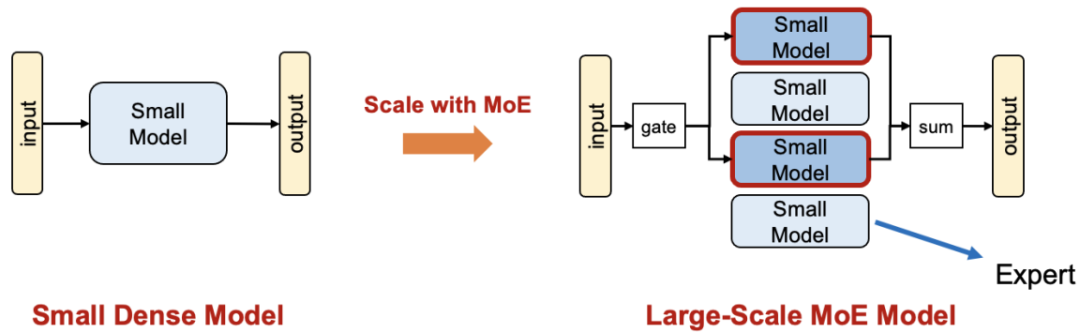
不同于稠密模型直接通过增大模型尺寸实现扩展,如图一所示,MoE 技术通过将一个小模型转变为多个稀疏激活的小模型实现参数扩展。由于各个专家在训练时稀疏激活,MoE 模型得以在不增加每轮迭代计算量的前提下增加模型参数量;从而有望在相同训练时间内获得更强的模型能力。
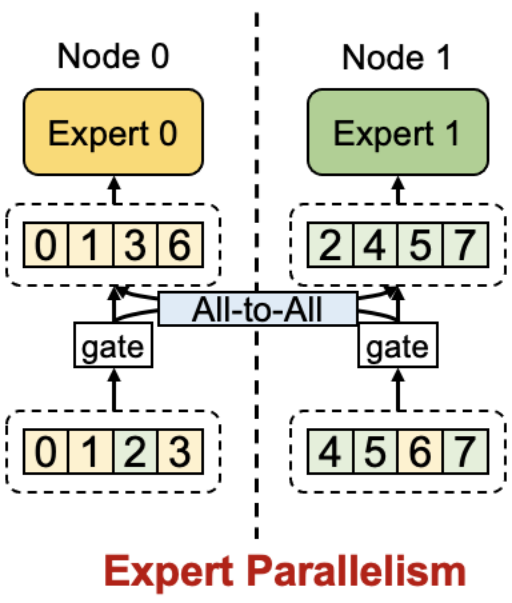
为了实现 MoE 大模型的分布式训练,业界提出了专家并行(Expert Parallelism)技术。如图二所示,各个专家被分布式地存储在不同节点上,在训练过程中通过 all-to-all 通信将训练数据发送至对应专家所在节点。专家并行相较于数据并行(Data Parallelism)有更小的内存开销,因为专家参数无冗余存储。可以认为专家并行是一种针对 MoE 结构的模型并行(Model Parallelism)。
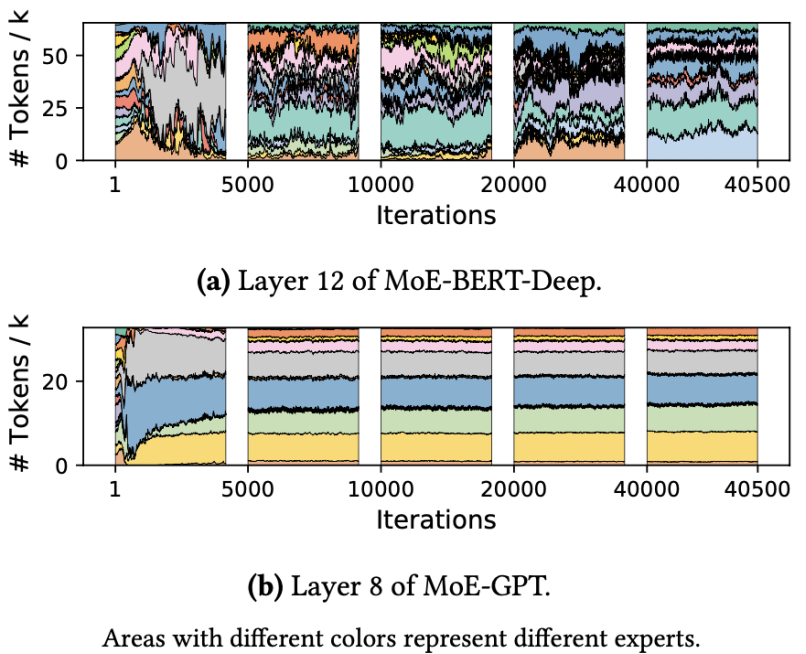
然而,使用朴素的专家并行技术训练 MoE 模型有严重的性能问题,其根因是 MoE 模型的稀疏激活模式。它会导致节点间产生大量不规则 all-to-all 通信增加延迟、计算量负载不均造成硬件利用率低。如图三所示的真实模型训练过程中的专家选择分布,可以观察到专家间显著的负载不均现象,且分布随训练进行动态变化。
随着学界对各并行策略的深入研究,使用各并行策略的复杂组合(称为混合并行)进行大模型训练成为必要模式。混合并行的策略调优过程十分复杂,为了提高可用性,学界提出了自动并行算法自动搜索、调优混合并行策略。然而,现有混合并行、自动并行系统无法高效处理 MoE 大模型,他们缺少对 MoE 模型训练稀疏激活、计算负载不均且动态变化的特征的针对性设计。
为了实现 MoE 模型的高效训练,SmartMoE 系统对 MoE 模型的分布式训练策略进行了全面的支持。对于常用的四种并行策略(数据并行、流水线并行、模型并行和专家并行),SmartMoE 系统做出了全面的支持,允许用户对它们任意组合;在论文投稿时(2023 年 1 月),尚未有其他系统能做到这一点(如图四所示)。
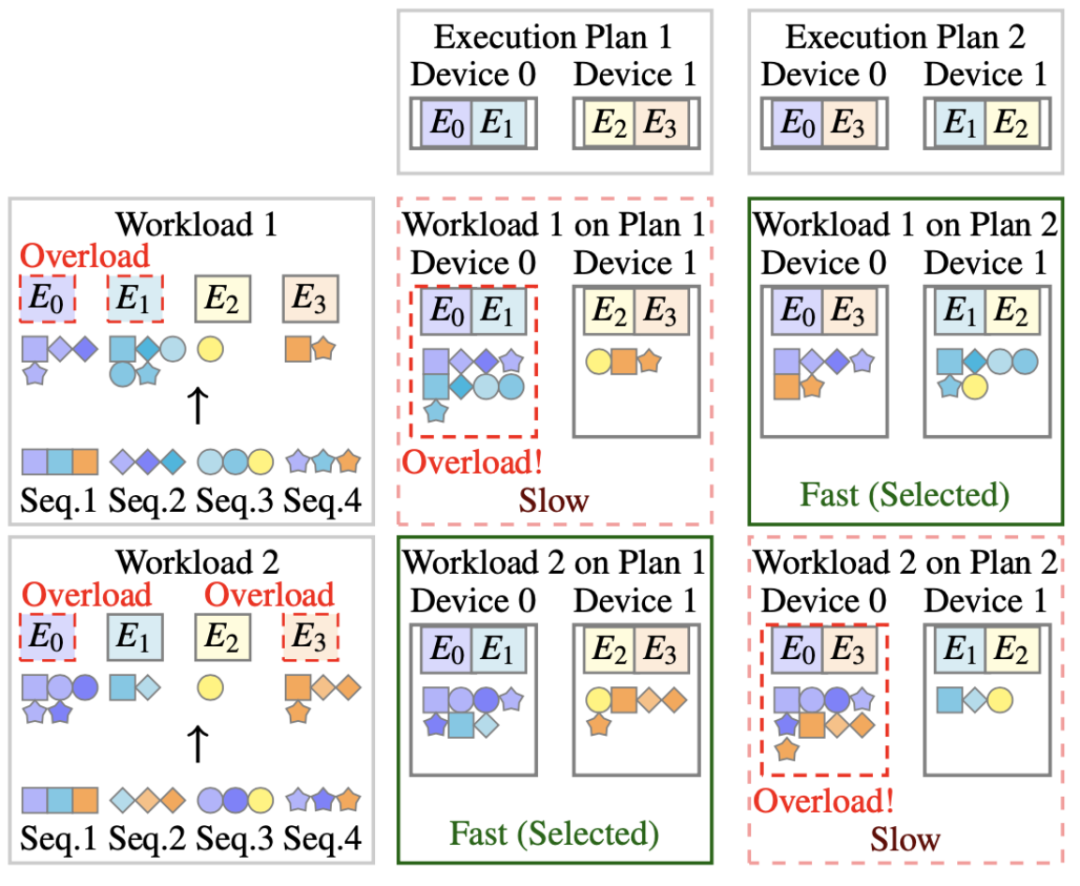
为了处理 MoE 的动态计算负载,SmartMoE 独特设计了专家放置(Expert Placement)策略,在经典并行策略组合的基础上,实现了动态负载均衡。如图五所示,MoE 模型不同的计算负载(workload)会造成不同专家的过载;使用不同的专家放置顺序,能在特定负载下实现节点间负载均衡。
为了提高 MoE 模型复杂混合并行策略的易用性,SmartMoE 设计了一套轻量级且有效的两阶段自动并行算法。现有自动并行系统只能在训练开始前进行策略搜索,无法根据负载情况动态调整策略。简单的将现有自动并行搜索算法在训练过程中周期性使用亦不可行,因为训练过程中的并行策略搜索和调整对延迟要求很高,现有算法的开销过大。
SmartMoE 独创性地将自动并行搜索过程分为两阶段:
最终,SmartMoE 实现了轻量级且有效的自动并行,达到了业界领先的性能。
在性能测试中,SmartMoE 在不同模型结构、集群环境和规模下均有优异的表现。例如,在 GPT-MoE 模型的训练性能测试中,相较于 FasterMoE,SmartMoE 有最高 1.88x 的加速比。值得注意的,在对每一轮迭代的性能观察中发现,动态的并行策略调整是必要的,且需要使用合适的调整频率。