
计算机视觉研究院专栏
作者:Edison_G
京东AI研究院提出的一种新的注意力结构。将CoT Block代替了ResNet结构中的3×3卷积,来形成CoTNet,在分类检测分割等任务效果都出类拔萃!
1
2
Attention注意力机制与self-attention自注意力机制
-
为什么要注意力机制?
在Attention诞生之前,已经有CNN和RNN及其变体模型了,那为什么还要引入attention机制?主要有两个方面的原因,如下:
(1)计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
(2)优化算法的限制:LSTM只能在一定程度上缓解RNN中的长距离依赖问题,且信息“记忆”能力并不高。
-
什么是注意力机制
在介绍什么是注意力机制之前,先让大家看一张图片。当大家看到下面图片,会首先看到什么内容?当过载信息映入眼帘时,我们的大脑会把注意力放在主要的信息上,这就是大脑的注意力机制。
3
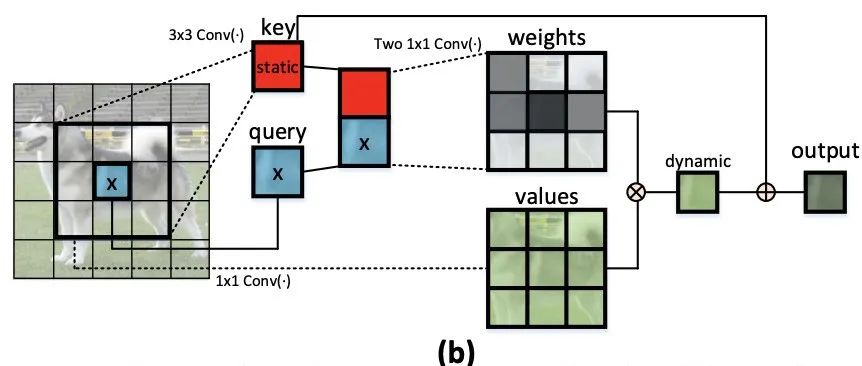
在这里,研究者提出了视觉主干中可扩展的局部多头自注意力的一般公式,如上图(a)所示。形式上,给定大小为H ×W ×C(H:高度,W:宽度,C:通道数)的输入2D特征图X,将X转换为查询Q = XWq,键K=XWk,值V = XWv,分别通过嵌入矩阵 (Wq, Wk, Wv)。 值得注意的是,每个嵌入矩阵在空间中实现为1×1卷积。
局部关系矩阵R进一步丰富了每个k × k网格的位置信息:
接下来,注意力矩阵A是通过对每个头部的通道维度上的Softmax操作对增强的空间感知局部关系矩阵Rˆ进行归一化来实现的:A = Softmax(Rˆ)。将A的每个空间位置的特征向量重塑为Ch局部注意力后矩阵(大小:k × k),最终输出特征图计算为每个k × k网格内所有值与学习到的局部注意力矩阵的聚合:
2、Contextual Transformer Block
传统的自注意力很好地触发了不同空间位置的特征交互,具体取决于输入本身。然而,在传统的自注意力机制中,所有成对的查询键关系都是通过孤立的查询键对独立学习的,而无需探索其间的丰富上下文。这严重限制了自注意力学习在2D特征图上进行视觉表示学习的能力。
为了缓解这个问题,研究者构建了一个新的Transformer风格的构建块,即上图 (b)中的 Contextual Transformer (CoT) 块,它将上下文信息挖掘和自注意力学习集成到一个统一的架构中。
3、Contextual Transformer Networks
ResNet-50 (left) and CoTNet50 (right)
ResNeXt-50 with a 32×4d
template (left) and CoTNeXt-50 with a 2×48d template (right).
4
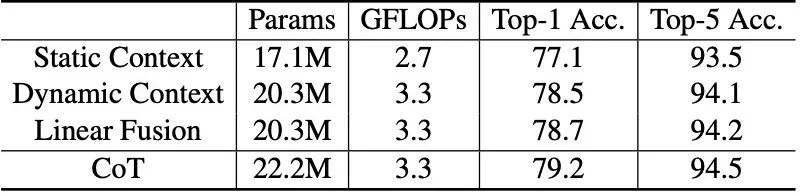
探索上下文信息的不同方式的性能比较,即仅使用静态上下文(Static Context),只使用动态上下文(Dynamic Context),线性融合静态和动态上下文(Linear Fusion),以及完整版的CoT块。 主干是CoTNet-50和采用默认设置在ImageNet上进行训练。
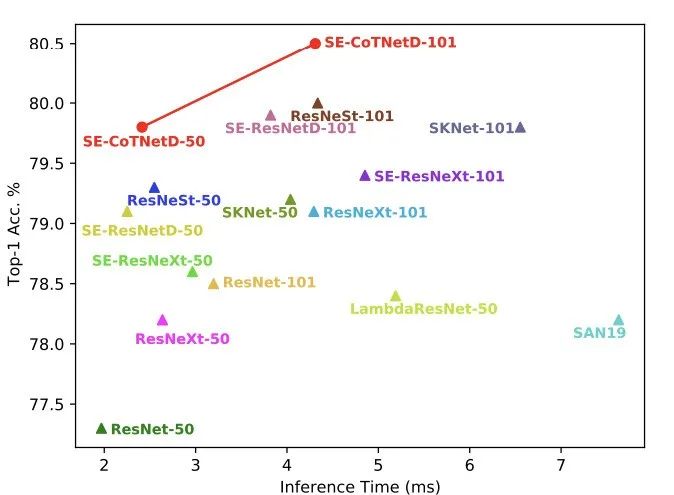
在ImageNet数据集上的Inference Time vs. Accuracy Curve
上表总结了在COCO数据集上使用Faster-RCNN和Cascade-RCNN在不同的预训练主干中进行目标检测的性能比较。 将具有相同网络深度(50层/101层)的视觉主干分组。 从观察,预训练的CoTNet模型(CoTNet50/101和CoTNeXt-50/101)表现出明显的性能,对ConvNets 主干(ResNet-50/101和ResNeSt-50/101) 适用于所有IoU的每个网络深度阈值和目标大小。 结果基本证明了集成self-attention学习的优势使用CoTNet中的上下文信息挖掘,即使转移到目标检测的下游任务。
不同主干的检测结果demo:
CoTNeXt-50
CoTNet50
CoTNet50
CoTNeXt-50
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
?
-
YOLOS:通过目标检测重新思考Transformer(附源代码) -
自己觉得挺有意思的目标检测框架,分享给大家(源码论文都有) -
CVPR2021:IoU优化——在Anchor-Free中提升目标检测精度(附源码) -
多尺度深度特征(上):多尺度特征学习才是目标检测精髓(干货满满,建议收藏) -
多尺度深度特征(下):多尺度特征学习才是目标检测精髓(论文免费下载) -
ICCV2021目标检测:用图特征金字塔提升精度(附论文下载) -
CVPR21小样本检测:蒸馏&上下文助力小样本检测(代码已开源) -
半监督辅助目标检测:自训练+数据增强提升精度(附源码下载) -
目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载) -
目标检测新框架CBNet | 多Backbone网络结构用于目标检测(附源码下载) -
CVPR21最佳检测:不再是方方正正的目标检测输出(附源码) -
Sparse R-CNN:稀疏框架,端到端的目标检测(附源码) -
利用TRansformer进行端到端的目标检测及跟踪(附源代码)
相关文章
