文章概览:ChatGPT进化轨迹;大模型物种进化图;大模型排行榜
硬核上手
还能这么玩?清华给ChatGPT 做逆向,发现了 ChatGPT的进化轨迹!
文章来源: 夕小瑶科技说
-
清华研究团队构建数据集记录 ChatGPT 版本迭代:通过构建按月和按日记录 ChatGPT 变化的数据集,分析其进化轨迹,揭示了模型的改进和发展趋势。
-
ChatGPT 在攻击性文本分类、数学推理等方面有显著提升:New ChatGPT 在攻击性与垃圾文本分类任务中几乎接近 SOTA,数学推理方面也取得了显著进步,但依赖先验知识的任务性能有所下降。
-
聚焦特征稳定性分析:通过分析语义特征、情感特征和语言特征等总计 265 个特征,论文发现 ChatGPT 在语义丰富度方面得到了加强,可读性和语义清晰度是其最稳定且表现最佳的核心竞争力。


两周时间,我体验了GPT-4 从编程神器变成编程智障!
文章来源:CSDN
-
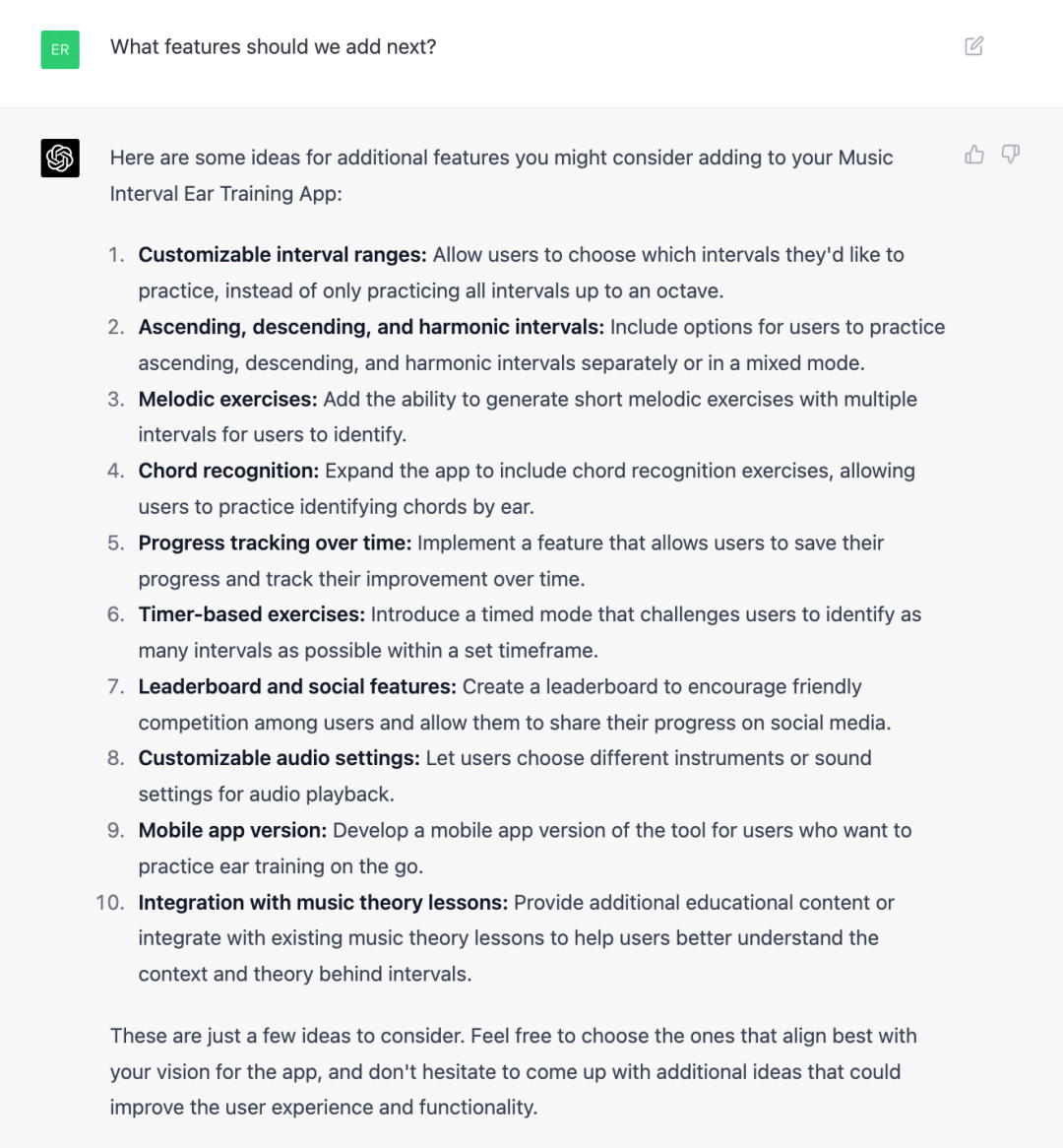
关于音程听力训练应用的功能建议:GPT-4 提出了一系列可能的功能添加,包括自定义音程范围、上行/下行/和声音程、旋律练习、和弦识别、进度跟踪、计时练习、排行榜和社交功能、自定义音频设置、移动应用和集成音乐理论课程。
-
代码生成问题:尽管 GPT-4 提供了一些实现功能的代码片段,但它们可能存在问题,例如引用了不存在的变量和函数,或者忽略了上下文和需求。
-
无效技巧:在尝试多种方法(阐明需求、提醒代码、要求它倒退一步、开启新的聊天会话、要求它加倍小心、人为介入重构代码)后,GPT-4 仍然未能生成可运行的代码。
-
有用的技巧:要求 GPT-4 为代码生成文档。为函数添加详细的文档说明后,GPT-4 成功生成了可运行的代码。
-
学会与 GPT-4 合作:经过反复尝试,作者学会了如何与 GPT-4 一起工作,并对其他人是否遇到类似问题表示好奇。

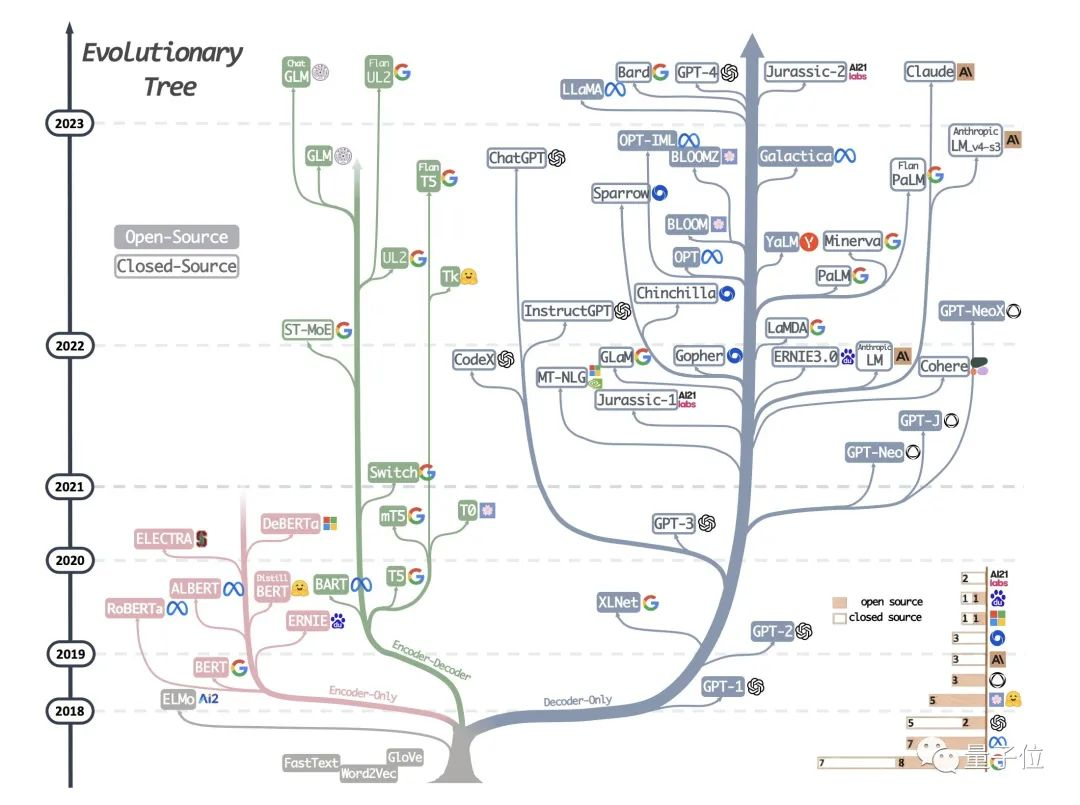
大模型物种进化图转疯了:8位华人打造,一眼看懂“界门纲目”,原来BERT后代已绝种
-
大语言模型发展方向:大语言模型的发展可以分为“BERT派”和“GPT派”,其中,BERT派以编码器架构为特征,分为编解码器和仅编码器两类;GPT派则主张保留解码器,现在以OpenAI为代表在LLM领域占据优势。
-
影响大模型性能的关键因素:数据类型对模型性能产生重要影响,包括预训练数据、微调数据和测试/用户数据,分别决定了模型的基本能力、特定任务性能和泛化能力。
-
选择适合实际任务的模型:根据任务需求,关注数据类型和模型性能指标,例如在自然语言理解任务中,微调模型通常优于LLM,而在知识密集型任务中,LLM则具备更丰富的现实世界知识,更适合使用。
-
任务特点与模型差异:LLM具有强大的泛化能力,但在特定任务或需求与所学知识不匹配的情况下,微调模型可能表现更好。

UC伯克利发布大语言模型排行榜!Vicuna夺冠,清华ChatGLM进前5
-
LLM排位赛概念:研究人员从LMSYS Org(UC伯克利主导)为大语言模型设计了一场排位赛,通过Elo得分对聊天机器人进行排名。
-
评估方法:用户与两个随机选择的聊天机器人进行1v1对战,根据聊天效果投票决定哪个表现更好。
-
难点:评估大语言模型非常困难,传统学术benchmark在聊天机器人上不好用,而雇佣人工评估又慢且昂贵。
-
Elo评分系统:广泛应用在竞技游戏和运动中,可实现可扩展性、增量性和唯一顺序,使评估更加公平和准确。


© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
