视频文本检索在多模态研究中起着至关重要的作用,在许多实际应用中得到了广泛的使用。CLIP(对比语言图像预训练)是一种图像语言预训练模型,它展示了从网络收集的图像文本数据集中学习视觉概念的能力。
在本文中,作者提出了一个CLIP4Clip 模型,以端到端的方式将CLIP模型的知识转移到视频语言检索中。在本文中,作者通过实验研究了以下几个问题:
1) 图像特征是否足以用于视频文本检索?
2) 基于CLIP的大规模视频文本数据集的后预训练如何影响性能?
3) 对视频帧之间的时间依赖性建模的实用机制是什么?
4) 该模型对视频文本检索任务的超参数敏感性。
大量实验结果表明,基于CLIP的CLIP4Clip模型可以在各种视频文本检索数据集上实现SOTA结果,包括MSR-VTT、MSVC、LSMDC、ActivityNet和DiDeMo。

CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
https://arxiv.org/abs/2104.08860
代码:
https://github.com/ArrowLuo/CLIP4Clip
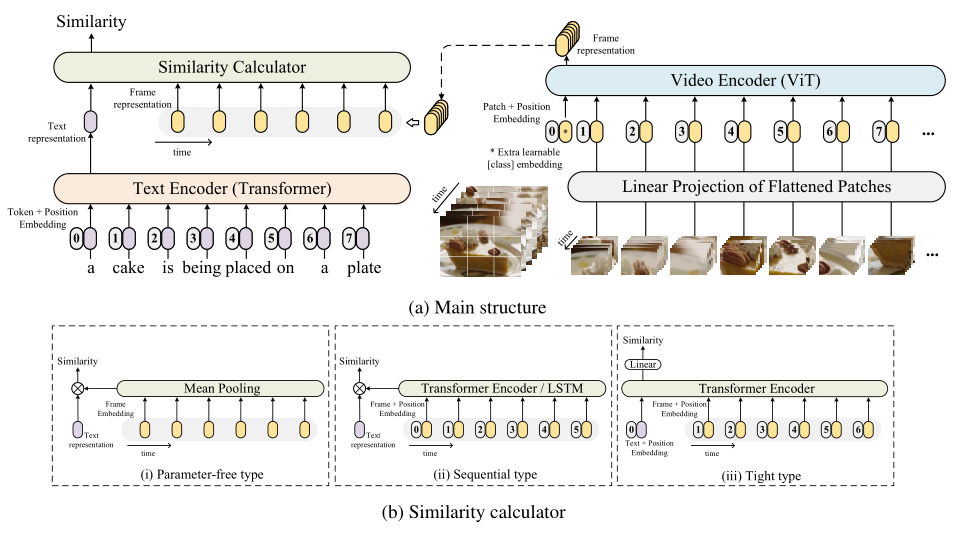
在本文中,作者利用预训练好的CLIP,提出了一个名为CLIP4Clip(CLIP For ** video Clip ** retrieval)的模型来解决视频文本检索问题。具体而言,CLIP4Clip构建在CLIP之上,并设计了一个相似度计算器来研究三种相似度计算方法:无参数型 、顺序型 和紧密型 。
与目前基于CLIP的工作相比,不同之处在于,他们的工作直接利用片段进行 zero-shot预测,而没有考虑不同的相似性计算机制。然而,本文设计了一些相似性计算方法来提高性能,并以端到端的方式训练模型。
此外,通过大量的实验,作者得出了以下结论:
1)单个图像远远不足以用于视频文本检索的视频编码。
2) 在CLIP4Clip模型上对大规模视频文本数据集进行后预训练是必需的,并且可以提高性能,特别是对于大幅度的零样本预测。
3) 基于强大的预训练CLIP,对于小数据集,最好不要引入新参数,对视频帧采用平均池化机制;对于大数据集,最好引入更多参数,以学习大型数据集的时间依赖性。
4)视频文本检索中使用的CLIP是学习率敏感的。
相关文章
